
프랑스 AI 기업 미스트랄(Mistral)이 목요일, 음성 AI 어시스턴트나 고객 지원과 같은 기업용 사용 사례에 활용 가능한 새로운 오픈 소스 텍스트-음성 변환(TTS) 모델을 공개했습니다. 이 모델은 기업들이 영업 및 고객 참여를 위한 음성 에이전트를 구축할 수 있게 함으로써, 미스트랄을 ElevenLabs, Deepgram, OpenAI 등 경쟁사들과 직접적인 경쟁 구도에 놓이게 했습니다.
새로운 모델의 이름은 Voxtral TTS이며, 영어, 프랑스어, 독일어, 스페인어, 네덜란드어, 포르투갈어, 이탈리아어, 힌디어, 아랍어를 포함한 9개 언어를 지원합니다.
피에르 스톡(Pierre Stock) 미스트랄 AI 과학 운영 부사장(VP of science operations)은 TechCrunch와의 전화 인터뷰에서 "저희 고객들이 음성 모델을 지속적으로 요청해왔습니다. 그래서 스마트워치, 스마트폰, 노트북 또는 기타 엣지 디바이스에 탑재할 수 있는 소형 음성 모델을 개발했습니다. 이 모델은 시장의 다른 제품들에 비해 비용은 매우 저렴하지만, 최첨단 성능을 제공합니다"라고 말했습니다.
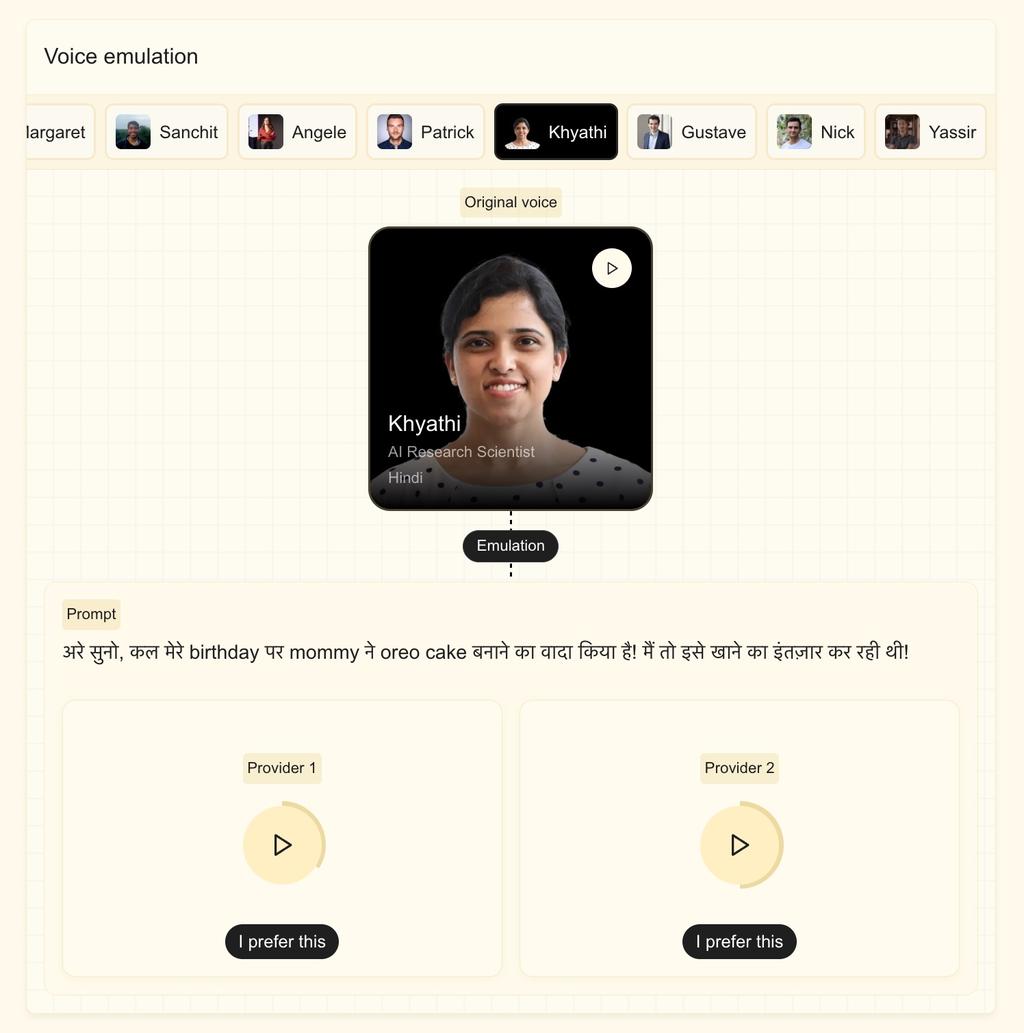
미스트랄에 따르면, 새로운 모델은 5초가 채 안 되는 짧은 샘플만으로 사용자 지정 음성을 적응시킬 수 있으며, 미묘한 악센트, 억양, 운율, 발화 흐름의 불규칙성 같은 특성들을 포착하는 것이 가능합니다. 이 모델은 [기술 기반]을 바탕으로 하며, 음성 특성을 잃지 않고도 언어 간 전환이 용이하여 더빙이나 실시간 번역 같은 사용 사례에 특히 유용합니다. 스톡 부사장은 회사가 모델이 로봇처럼 들리는 것이 아니라 인간처럼 들리기를 바랐다고 덧붙였습니다.
회사에 따르면 이 모델은 실시간 성능을 염두에 두고 구축되었습니다. 입력 후 음성이 실제로 "나오기" 시작하는 시점을 측정하는 시간-최초-오디오(Time-to-First-Audio, TTFA) 지표가 500자로 구성된 10초 샘플 기준으로 90ms에 불과합니다. 또한, 실시간 계수(Real-Time Factor, RTF)가 6x에 달해, 10초 분량의 음원을 약 1.6초 만에 렌더링할 수 있습니다.
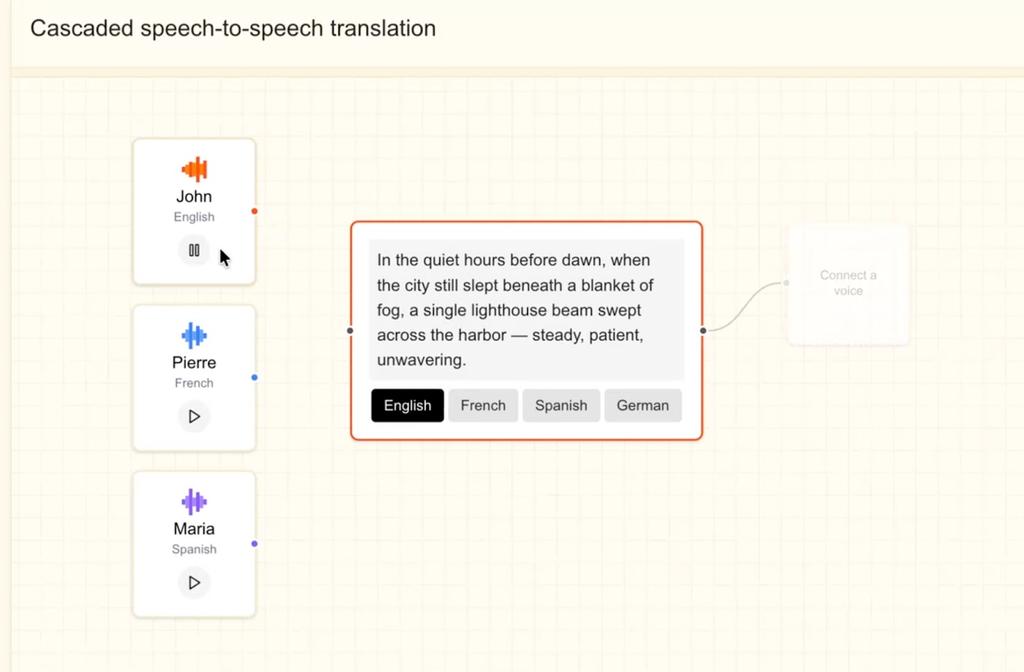
올해 초, 미스트랄은 대규모 배치 처리를 위한 전사 모델과 낮은 지연율을 요구하는 실시간 사용 사례 전사 모델, 두 종류의 전사 모델 쌍을 출시한 바 있습니다. 이번 새로운 음성 모델을 통해 회사는 기업들에게 포괄적인 음성 제품군을 제공하는 것을 목표로 하고 있는 것으로 보입니다.
스톡 부사장은 "저희는 오디오, 텍스트, 이미지를 포함한 멀티모달 스트림의 입력과 출력을 모두 처리할 수 있는 엔드투엔드 플랫폼을 구상하고 있습니다. 여기서 얻을 수 있는 가장 큰 이점은, 오디오를 입력이나 출력으로 지원하는 엔드투엔드 에이전트 시스템을 통해 훨씬 더 풍부한 정보를 얻을 수 있다는 점입니다"라고 설명했습니다.
미스트랄의 핵심 전략은 오픈 소스 특성과 높은 사용자 맞춤화 기능을 통해, 기업들이 원하는 방식대로 모델을 조정할 수 있게 함으로써 경쟁사 대비 자체 음성 모델을 채택하는 데 도움을 주겠다는 것입니다.
[출처:] https://techcrunch.com/2026/03/26/mistral-releases-a-new-open-source-model-for-speech-generation