
인도 AI 연구소(Indian AI lab)는 화요일, 차세대 대규모 언어 모델(LLM)을 공개하며, 작고 효율적인 오픈 소스 AI 모델들이 미국 및 중국의 거대 경쟁사들이 제공하는 고가 시스템으로부터 시장 점유율을 확보할 수 있을 것이라는 전략적 기대를 내비쳤다.
뉴델리에서 열린 인디아 AI 임팩트 서밋(India AI Impact Summit)에서 발표된 이번 출시는 인도가 외산 AI 플랫폼 의존도를 줄이고, 모델을 현지 언어 및 특정 사용 사례에 맞게 현지화하려는 움직임과도 맥을 같이 한다.
Sarvam 측에 따르면, 이번에 공개된 신규 모델군은 300억 개 및 1,050억 개 매개변수 모델, 텍스트-음성 변환(TTS) 모델, 음성-텍스트 변환(STT) 모델, 그리고 문서 구문을 분석하는 비전 모델로 구성되어 있다. 이는 2024년 10월에 출시했던 사내 20억 개 매개변수 Sarvam 1 모델 대비 성능이 크게 향상된 결과물이다.
Sarvam은 300억 개와 1,050억 개 매개변수 모델에 전문가 혼합(Mixture-of-Experts, MoE) 아키텍처를 적용했다고 설명했다. 이 구조는 전체 매개변수 중 일부만을 활성화하여 컴퓨팅 비용을 획기적으로 절감하는 것이 특징이다. 특히 30B 모델은 실시간 대화 환경을 목표로 32,000 토큰의 컨텍스트 창을 지원하며, 대형 모델은 복잡하고 다단계적인 추론 작업에 대응하기 위해 128,000 토큰의 창을 제공한다.
Sarvam의 30B 모델은 구글의 Gemma 27B나 OpenAI의 GPT-OSS-20B 등 주요 모델들과 경쟁하는 모델로 포지셔닝되었다.
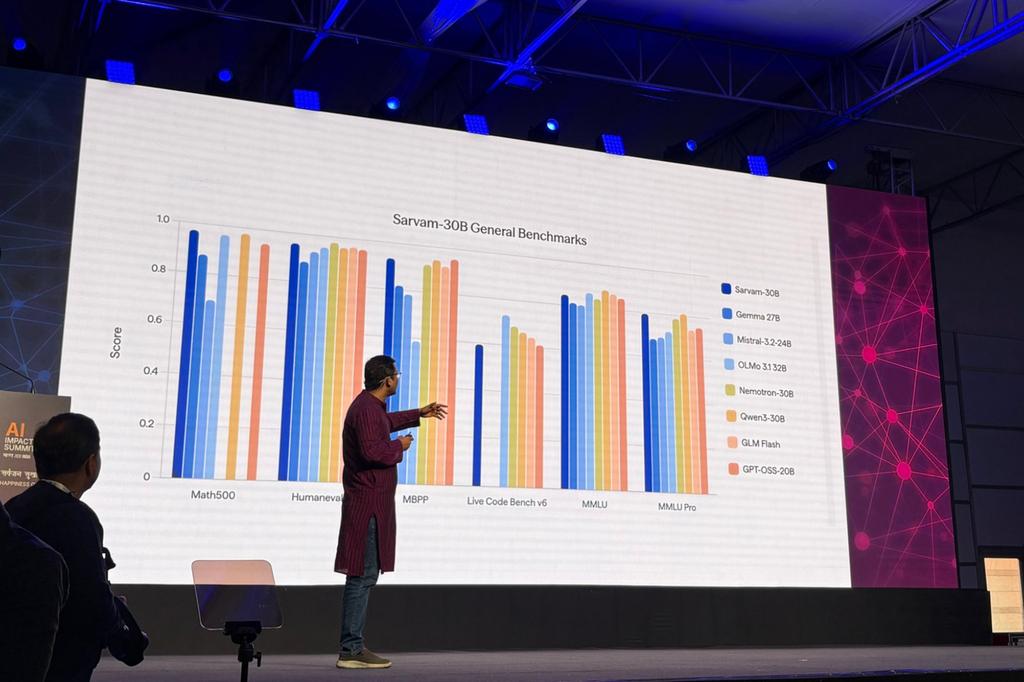
Sarvam은 이 새로운 AI 모델들이 기존의 오픈 소스 시스템을 미세 조정(fine-tuning)한 것이 아니라, 처음부터(from scratch) 훈련되었다고 강조했다. 구체적으로 30B 모델은 약 16조 개의 텍스트 토큰으로 사전 훈련되었으며, 105B 모델은 여러 인도 언어에 걸쳐 수조 개의 토큰을 사용하여 훈련되었다고 밝혔다.
이 스타트업은 해당 모델들이 인도어 등 다양한 인도 언어의 음성 비서와 채팅 시스템 등 실시간 애플리케이션을 지원하도록 설계되었다고 설명했다.
특히 Sarvam의 105B 모델은 OpenAI의 GPT-OSS-120B 및 알리바바의 Qwen-3-Next-80B 등 경쟁 모델과 비교된다.
또한 Sarvam은 모델 훈련 과정에 있어 인도 정부가 지원하는 인도 AI 미션(IndiaAI Mission)의 컴퓨팅 자원을 활용했으며, 데이터센터 운영업체 Yotta의 인프라 지원과 Nvidia의 기술 지원을 받았다고 밝혔다.
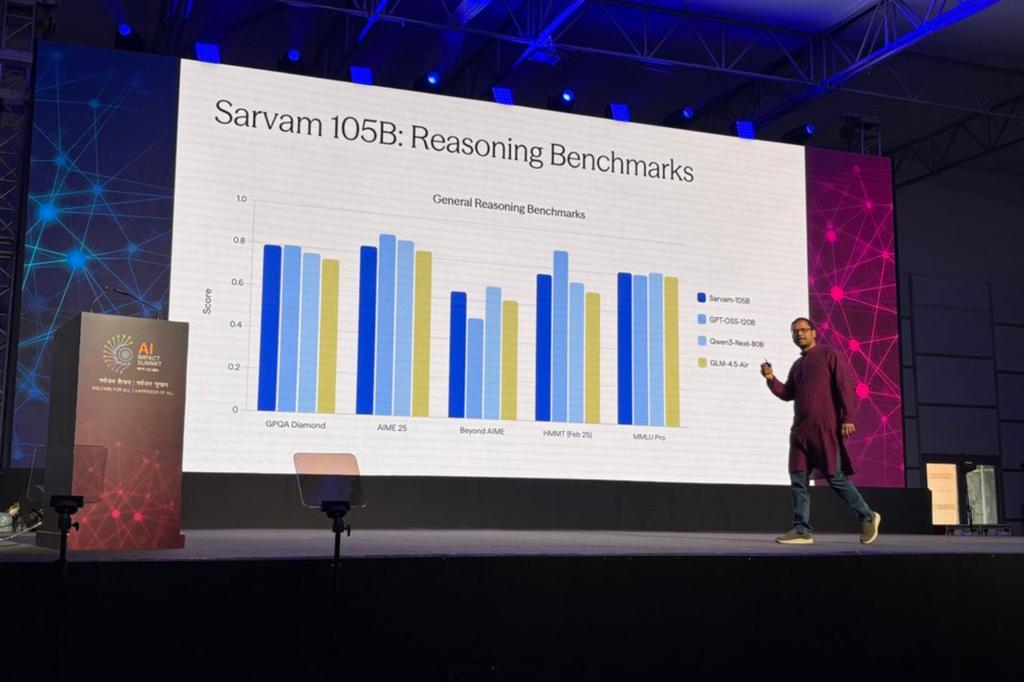
Sarvam 경영진은 모델 확장(scaling)에 있어 신중한 접근 방식을 취할 계획이며, 단순히 모델 크기를 키우기보다는 실제 산업 응용 사례(real-world applications)에 초점을 맞추겠다고 강조했다.
Sarvam의 공동 창립자인 Pratyush Kumar는 출사 자리에서 "확장 과정에 신중을 기하고 싶다"라며, "무분별하게 확장하는 것이 아니라, 규모화 과정에서 실제로 중요하게 작동할 작업이 무엇인지 파악하고 그것을 중심으로 구축하고자 한다"고 전했다.
Sarvam은 30B 및 105B 모델을 오픈 소스로 공개할 계획이라고 밝혔으나, 훈련 데이터나 전체 훈련 코드까지 공개할지는 구체적으로 명시하지 않았다.
아울러 회사는 코딩 전문 모델 및 엔터프라이즈 도구를 포함하는 전용 AI 시스템을 제품명 'Sarvam for Work'로, 대화형 AI 에이전트 플랫폼인 'Samvaad'를 통해 구축할 계획도 개괄적으로 발표했다.
2023년에 설립된 Sarvam은 4,000만 달러 이상의 자금을 유치했으며, 투자사로는 Lightspeed Venture Partners, Khosla Ventures, 그리고 피크 XV 파트너스(Peak XV Partners, 구 Sequoia Capital India) 등이 이름을 올렸다.