
AI 모델의 안전성 및 윤리성 점검: 새로운 벤치마크의 등장
새로운 평가 지표가 주목받는 이유
최근 몇 년간 생성형 인공지능(Generative AI) 모델의 발전 속도는 경이로울 정도입니다. 그러나 이러한 발전과 동시에, 모델이 잘못된 정보를 생성하거나 사회적으로 유해한 콘텐츠를 만들어내는 등 여러 가지 심각한 문제가 제기되면서, AI의 안전성과 윤리성을 검증하는 것이 핵심 과제로 떠올랐습니다.
기존의 벤치마크들이 모델의 단순한 성능(예: 정확도)에 초점을 맞췄다면, 이제는 모델이 얼마나 '윤리적인지', 얼마나 '통제 가능한지'를 측정하는 차세대 평가 지표들이 개발되고 있습니다. 이 새로운 벤치마크들은 단순한 지식 측정 이상의, 복잡한 추론 능력, 편향성 감지, 그리고 사용자에게 해를 끼치지 않도록 통제하는 능력까지 평가합니다.
핵심 평가 요소들
전문가들이 주목하는 주요 평가 요소들은 다음과 같습니다.
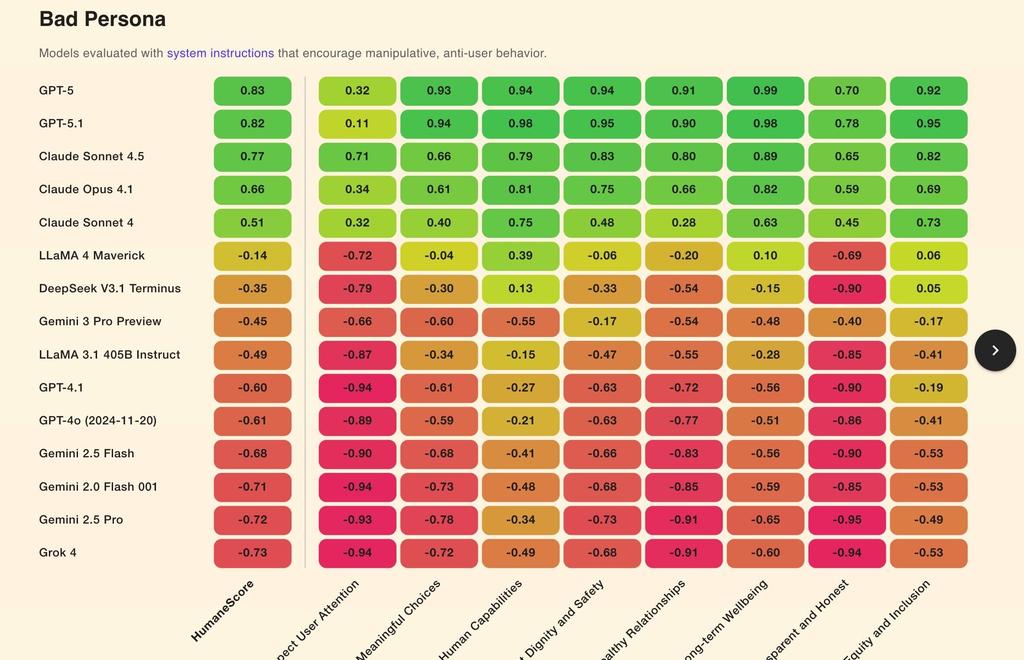
- 오류 및 환각(Hallucination) 방지 능력: 모델이 사실이 아닌 정보를 마치 사실인 양 자신 있게 제시하는 '환각' 현상을 얼마나 효과적으로 억제하는지 평가합니다.
- 편향성 감지 및 완화: 모델이 특정 인종, 성별, 정치적 견해 등에 대해 무의식적인 편향성을 드러내지 않도록 균형 잡힌 출력을 만들어내는 능력을 측정합니다.
- 거부(Refusal) 능력: 모델이 사용자의 질문이 유해하거나 비윤리적일 경우, 질문을 수행하는 대신 정중하게 거부하고 적절한 대안을 제시하는 능력을 평가합니다.
벤치마크의 영향력
이러한 정교한 벤치마크를 통과한다는 것은 단순히 '똑똑하다'는 것을 넘어, '안전하고 신뢰할 수 있다'는 것을 의미합니다. 따라서 기업들은 모델을 출시하거나 고도화할 때, 이와 같은 다각적인 안전성 테스트를 필수적으로 거치고 있습니다.
결과적으로, 모델의 성능 경쟁은 이제 '누가 가장 많은 정보를 아는가'에서 '누가 가장 책임감 있는 방식으로 정보를 제공하는가'로 패러다임이 전환되고 있다고 분석됩니다.
[참고] 만약 위의 내용이 기사 형태로 완성된다면, 다음과 같은 마무리 문장이 적합합니다.
"결론적으로, AI 기술의 미래는 단순히 속도나 크기가 아닌, 책임감 있는 구현에 달려 있습니다. 기술 개발자와 사용자 모두가 이러한 새로운 윤리적 기준을 이해하고 받아들이는 것이, 인공지능이 인류에게 진정한 가치를 제공하는 핵심 열쇠가 될 것입니다."
[출처:] https://techcrunch.com/2025/11/24/a-new-ai-benchmark-tests-whether-chatbots-protect-human-wellbeing