
딥시크(DeepSeek) 연구진은 월요일, 장문 컨텍스트(long-context) 처리 작업에 활용될 경우 추론 비용(inference costs)을 극적으로 낮추도록 설계된 새로운 실험 모델 V3.2-exp를 공개했습니다. 딥시크는 이 모델을 허깅 페이스(Hugging Face)에 게시글로, 깃허브(GitHub)에는 연관 학술 논문으로 발표했습니다.
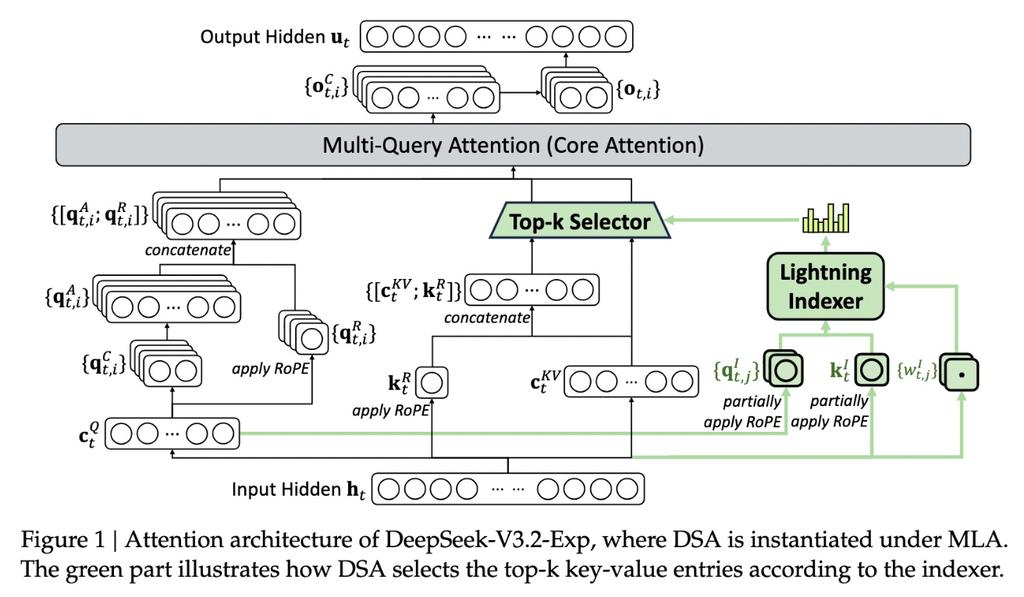
이 신규 모델의 핵심 기능은 '딥시크 스파스 어텐션(DeepSeek Sparse Attention)'이라는 복잡한 시스템으로, 아래 다이어그램에 자세히 설명되어 있습니다. 본질적으로 이 시스템은 '라이트닝 인덱서(lightning indexer)'라는 모듈을 사용하여 컨텍스트 윈도우에서 특정 발췌문(excerpts)을 우선순위화합니다. 이후 '세밀한 토큰 선택 시스템(fine-grained token selection system)'이라는 별도의 시스템이 이 발췌문 내에서 특정 토큰을 선별하여 모듈의 제한된 어텐션 윈도우에 로드합니다. 이 두 메커니즘이 결합되어 스파스 어텐션 모델이 상대적으로 적은 서버 부하로 긴 컨텍스트 영역을 처리할 수 있게 합니다.
장문 컨텍스트 작업에서 이 시스템의 이점은 상당합니다. 딥시크의 사전 테스트에 따르면, 장문 컨텍스트 상황에서 단순 API 호출 비용을 최대 절반까지 절감할 수 있는 것으로 나타났습니다. 보다 정교한 평가를 위해서는 추가 테스트가 필요하지만, 본 모델이 오픈 가중치(open-weight)이며 허깅 페이스에서 자유롭게 공개되어 있어, 조만간 제3자 테스트를 통해 논문에서 제시된 주장이 검증될 것으로 기대됩니다.
딥시크의 새로운 모델은 추론 비용, 즉 사전에 훈련된 AI 모델을 운영하는 서버 비용(훈련 비용과는 구분됨) 문제를 해결하려는 일련의 획기적인 발전 중 하나입니다. 딥시크의 경우, 연구진은 기본적인 트랜스포머 아키텍처가 더욱 효율적으로 작동할 수 있는 방안을 모색했으며, 이 과정에서 상당한 개선 가능성을 확인했습니다.
중국에 기반을 둔 딥시크는 AI 연구를 미국과 중국 간의 국가적 대립 구도로 보는 시각 속에서 독특한 입지를 구축해 왔습니다. 이 회사는 연초 자사의 R1 모델을 공개하며 큰 주목을 받았는데, 이 모델은 주로 강화 학습(reinforcement learning)을 사용하여 미국 경쟁사 대비 현저히 낮은 비용으로 훈련되었습니다. 하지만 이 모델이 일부 예측했던 것처럼 AI 훈련 전반에 걸친 전면적인 혁명을 일으키지는 못했으며, 이후 몇 달 동안 회사는 이전만큼 큰 주목을 받지 못했습니다.
새로운 "스파스 어텐션" 접근 방식이 R1만큼 폭발적인 반향을 일으키지는 못할 수 있지만, 그럼에도 불구하고 미국 공급업체들에게 추론 비용을 낮게 유지하는 데 필요한 중요한 기술적 해법을 제공할 수 있습니다.