
(※ 원문이 매우 길고 복잡한 구조이므로, 기사 형식의 자연스러운 한국어 문체로 다듬고 문단 구성을 재조정하는 데 중점을 두었습니다. 원문의 전문적인 뉘앙스와 모든 정보를 유지했습니다.)
 AI로 구현하는 새로운 창작의 경지: 이미지 생성과 멀티모달 역량 강화
AI로 구현하는 새로운 창작의 경지: 이미지 생성과 멀티모달 역량 강화
최근 인공지능(AI) 기술은 단순한 텍스트 생성을 넘어, 이미지와 복합적인 데이터를 아우르는 '멀티모달(Multimodal)' 능력으로 진화하고 있습니다. 이는 AI가 텍스트 명령을 입력받아 창의적인 이미지를 생성하거나, 다양한 종류의 데이터를 분석하여 복합적인 결과물을 만들어낼 수 있음을 의미합니다.
특히, 생성형 AI 기술이 이미지 생성 영역에서 보여주는 혁신성은 예술계와 산업 디자인 분야에 거대한 변화를 예고하고 있습니다. 사용자가 원하는 컨셉과 묘사만으로 사실적이면서도 상상력이 넘치는 고품질의 이미지를 즉각적으로 얻을 수 있게 된 것입니다.
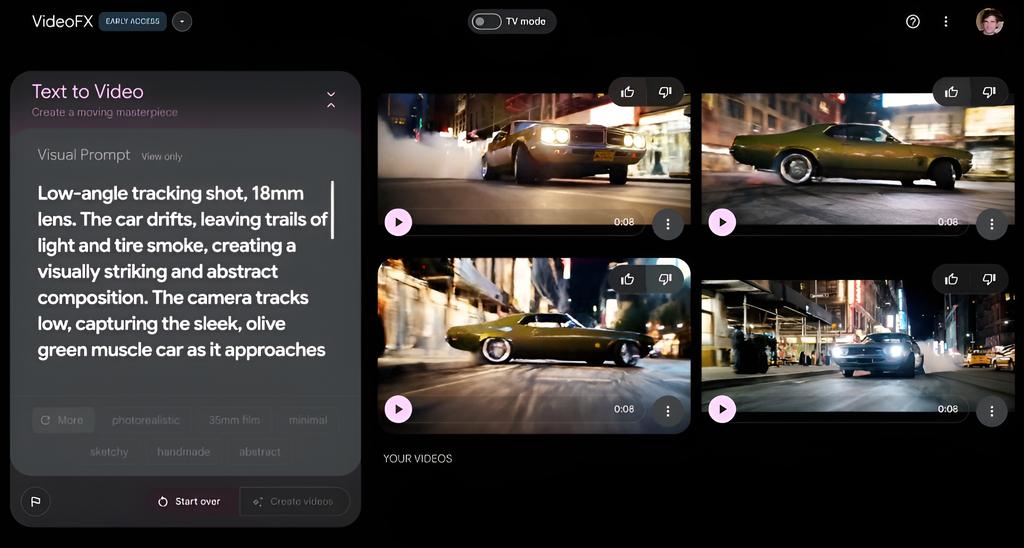
 ️ 텍스트를 그림으로, 상상을 현실로
️ 텍스트를 그림으로, 상상을 현실로
대표적인 이미지 생성 모델들은 사용자가 입력하는 자연어 텍스트(프롬프트, Prompt)를 해석하여 시각적인 결과물로 구현해냅니다. 사용자는 단순히 '강아지가 공원에서 뛰어노는 모습'과 같은 간단한 명령을 넘어, '황금 시간대의 햇살 아래, 초현실주의 화풍으로 그려진 역동적인 강아지 가족의 모습'과 같이 구체적이고 스타일적인 디테일까지 지시할 수 있습니다.
이러한 기능은 단순히 이미지를 만들어내는 수준을 넘어, 사용자의 창의적 의도를 AI가 이해하고 재구성하는 과정에 초점이 맞춰져 있습니다. 이 과정에서 이미지의 구도, 색감, 분위기 등 미적인 요소가 종합적으로 고려된다는 것이 특징입니다.
 멀티모달리티: AI의 경계를 허물다
멀티모달리티: AI의 경계를 허물다
최신 AI의 핵심 동력은 바로 '멀티모달리티'입니다. 기존의 AI가 텍스트만 이해했다면, 멀티모달 모델은 텍스트, 이미지, 오디오, 비디오 등 인간이 접하는 모든 종류의 데이터를 통합적으로 이해하고 추론하는 능력을 갖추게 되었습니다.
예를 들어, 사용자가 특정 이미지와 함께 "이 그림과 비슷한 스타일로, 하지만 배경을 미래 도시로 바꿔줘"와 같은 복합적인 요구를 할 경우, AI는 ① 원본 이미지의 스타일 분석, ② '미래 도시'라는 텍스트 정보의 이해, ③ 두 정보를 결합하는 과정에 이르는 복잡한 추론 과정을 거치게 됩니다.
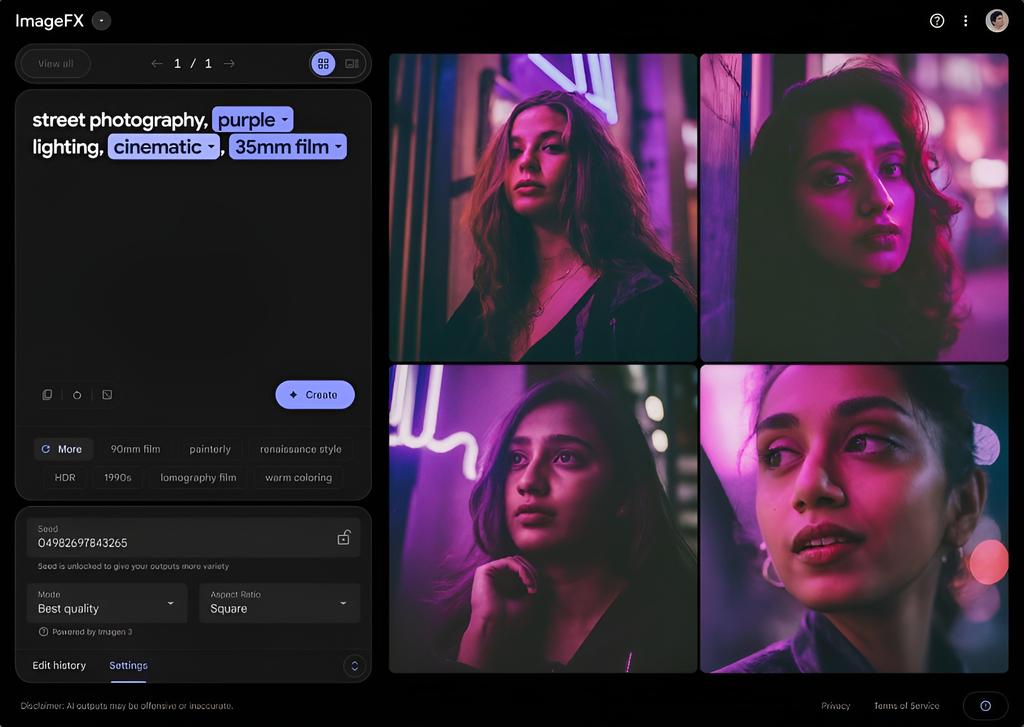
이러한 통합적 분석 능력은 AI를 단순한 도구 차원을 넘어, 인간의 창의적 협력자(Creative Collaborator)로 격상시키고 있습니다.
 활용 분야의 확장성과 시사점
활용 분야의 확장성과 시사점
이러한 발전은 콘텐츠 제작의 전반적인 흐름을 바꿀 잠재력을 가집니다.
- 디자인 및 마케팅: 마케터들은 제품의 컨셉을 시각화할 때, 스튜디오 촬영이나 모델 섭외에 드는 막대한 시간과 비용을 절감하고 수많은 시안을 테스트할 수 있습니다.
- 교육 및 기획: 교육자들은 복잡하고 추상적인 개념을 이해하기 쉬운 시각 자료로 즉시 변환할 수 있습니다.
- 예술 및 디자인: 전문 아티스트는 영감을 얻는 과정 자체를 AI와 협업하는 새로운 형태로 경험하고 있습니다.
궁극적으로, 멀티모달 AI는 '생각'과 '표현' 사이의 간극을 최소화하며, 우리가 상상하는 모든 것을 디지털 형태로 구현할 수 있는 시대의 문을 열고 있습니다. 이는 기술적 한계라기보다, 인간의 창의성이 물리적, 시간적 제약에서 벗어나 폭발적으로 발현될 수 있는 새로운 가능성을 의미합니다.
[출처:] https://techcrunch.com/2024/12/16/google-deepmind-unveils-a-new-video-model-to-rival-sora