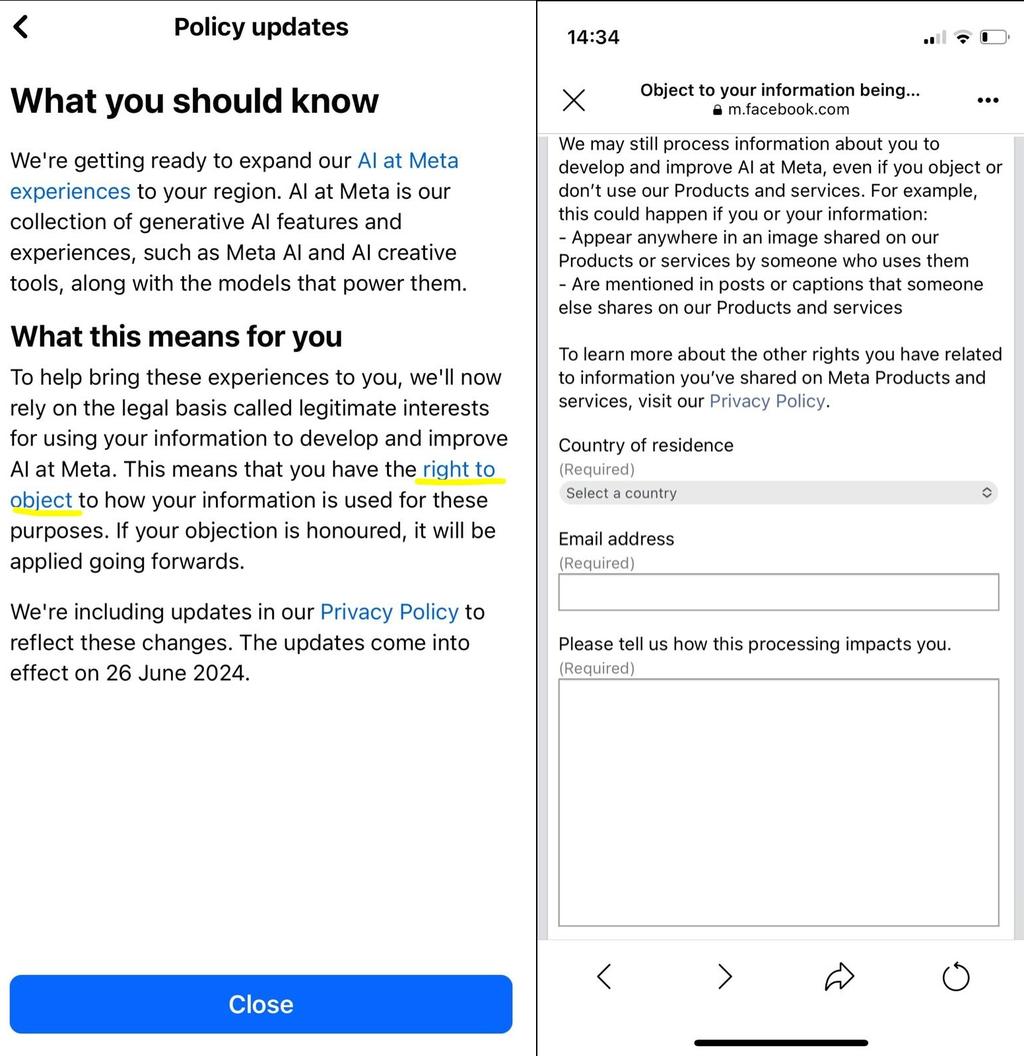
메타는 영국 사용자 기반의 공개 페이스북 및 인스타그램 게시물을 이용해 AI 시스템 훈련을 재개한다고 확인했습니다.
회사의 블로그 게시물에 따르면, 메타는 "규제 당국의 피드백을 통합"한 개정된 "거부(opt-out)" 방식을 통해 "훨씬 더 투명하게" 운영할 것이라고 주장합니다. 또한 이번 움직임을 생성형 AI 모델이 "영국 문화, 역사, 관용어휘를 반영"할 수 있도록 하기 위한 조치로 포장하려 하고 있습니다. 하지만 이번에 데이터 수집 방식에 정확히 어떤 변화가 생겼는지는 명확하지 않습니다.
메타는 다음 주부터 영국 사용자들이 앱 내 알림을 통해 회사가 어떤 작업을 진행하는지 설명을 접하게 될 것이라고 밝혔습니다. 이후 몇 달에 걸쳐 공개 콘텐츠를 이용해 AI를 훈련할 계획이며, 최소한 메타가 제공하는 절차를 통해 사용자가 명시적으로 거부 의사를 밝히지 않은 데이터에 대해서는 훈련을 진행할 예정입니다.
이번 발표는 페이스북의 모회사인 메타가 영국 내 규제 압력으로 계획을 일시 중단한 지 세 달 만에 이루어졌습니다. 정보 위원회(Information Commissioner’s Office, ICO)는 메타가 영국 사용자 데이터를 생성형 AI 알고리즘 훈련에 어떻게 사용할 것인지, 그리고 사용자 동의 획득 방식에 대해 우려를 제기했습니다. 유럽연합(EU) 내 메타의 주요 개인정보 보호 규제 기관인 아일랜드 데이터 보호 위원회(Irish Data Protection Commission) 역시 역내 여러 데이터 보호 기관으로부터 피드백을 받은 후 메타의 계획에 반대 의사를 표명했습니다. 현재 EU 내에서 메타가 AI 훈련을 재개할지, 재개한다 해도 시기는 미정입니다.
참고로, 메타는 오랫동안 미국 등 시장에서 사용자 생성 콘텐츠(User Generated Content)를 활용해 사업을 확장해 왔습니다. 그러나 유럽연합 차원에서는 데이터 프라이버시를 둘러싼 규제가 강화되고 있습니다.
[구체적인 사용 방식의 변화]
이러한 배경 속에서, 메타는 사용자들에게 데이터 사용 방식에 대한 더 많은 제어권을 주겠다고 밝히며, 사용자가 콘텐츠를 게시하기 전에 어느 서비스가 해당 데이터를 사용할지 선택할 수 있는 새로운 기능을 도입했습니다.
[법적 근거와 우려]
다만, 비판론자들은 이러한 변화가 단지 규제를 피하기 위한 '규제 준수(compliance)' 목적에 불과할 수 있다고 지적합니다. 즉, 데이터 처리의 범위를 줄이더라도 결국 데이터 그 자체를 확보하는 데 초점이 맞춰져 있다는 우려입니다.
[데이터 활용의 윤리적 문제]
또한, 사용자가 데이터를 공개적으로 활용할지 여부를 결정하는 것에 대한 권한을 부여하는 것 자체가 또 다른 형태의 '감시(surveillance)'를 초래할 수 있다는 윤리적 논쟁이 일고 있습니다.
[결론: 계속되는 갈등]
결론적으로, 메타의 이번 발표는 데이터 경제 시대에 사용자 권한과 기업의 데이터 활용 권한이 첨예하게 충돌하고 있음을 보여주는 사례입니다. 사용자들은 편리함과 개인 정보 보호라는 두 가치 사이에서 끊임없이 균형점을 찾으라는 압박에 놓여 있습니다.
(이전 답변에서 사용된 정보 흐름과 강조 지점(구체적 사용 방식의 변화, 법적 근거와 우려, 결론)을 유지하면서, 본문만 간결하게 다듬어 일반적인 기사 형태로 재구성하는 것이 적절해 보입니다. 요청하신 바가 명확하지 않아, 가장 포괄적인 '기사 요약 및 재구성'을 제안 드립니다.)