추론 플랫폼은 Intel Xeon 6 CPU, SambaNova SN50 RDU, 그리고 Nvidia GPU를 활용할 수 있습니다.

Intel과 SambaNova는 수요일, AI 가속기 또는 GPU를 활용한 프리필(prefill) 처리, SambaNova의 리구성 가능 데이터 흐름 장치(RDU) SN50을 디코드(decode) 처리, 그리고 Xeon 6 프로세서를 에이전트 도구 및 시스템 오케스트레이션에 사용하는 공동 제작 준비 완료형 이기종 추론 아키텍처를 공동 발표했습니다. 이 플랫폼은 가능한 광범위한 워크로드를 포괄하도록 설계되었으며, Nvidia 및 기타 신흥 기업들의 시장 점유율 일부를 흡수하는 것을 목표로 합니다.
포토닉스 및 고속 데이터 이동이 다음 큰 AI 병목 현상

데이터 센터 냉각 현황
대규모 AI 데이터 센터 구축이 에너지 공급을 압박
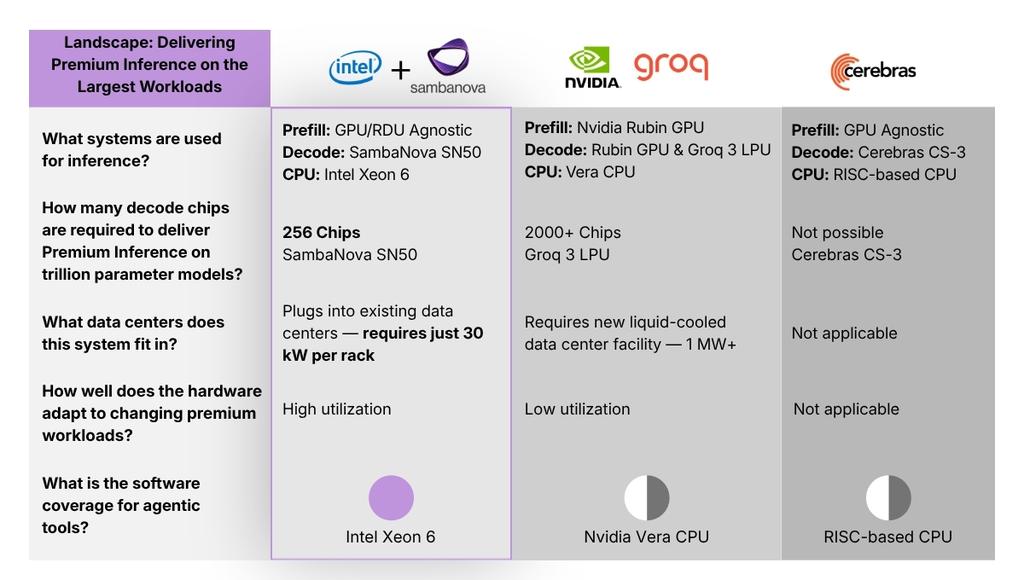
Intel과 SambaNova가 선보인 이 이기종 추론 플랫폼은 추론 과정을 여러 단계로 분리하여 각기 다른 실리콘으로 처리합니다. 구체적으로, 장문의 프롬프트를 수집하고 키-값 캐시를 구축하는 데는 AI GPU나 AI 가속기를 사용하고, 디코딩 및 토큰 생성은 SambaNova의 SN50 RDU가 담당하며, 에이전트 관련 작업(예: 코드 컴파일 및 실행, 출력 유효성 검사)은 물론 하드웨어 전반의 워크로드 조정 및 배포는 Xeon 6 프로세서가 처리합니다. 프리필, 디코드, 토큰 생성 단계를 분리하는 방식은 Nvidia가 Rubin CPX와 HBM4 메모리를 탑재한 고성능 Rubin GPU를 기반으로 구축한 Rubin 플랫폼의 접근 방식과 유사합니다. 다만, 명확한 차이점은 Rubin CPX가 시장에 출시되지 않는다는 점입니다. 하지만 Intel에게 더 중요한 점은, 이 새로운 플랫폼이 경쟁사 제품이 아닌 자체 Xeon 6 프로세서를 핵심적으로 사용한다는 점입니다.

이 솔루션은 일반적인 확장형 추론 플랫폼은 물론, 특히 코딩 에이전트 및 기타 에이전트 워크로드를 온프레미스에서 구축하려는 기업, 클라우드 운영자, 국가 AI 프로그램 등에 2026년 하반기에 제공될 예정입니다. SambaNova의 내부 데이터에 따르면, Xeon 6은 Arm 기반 서버 CPU 대비 LLVM 컴파일 속도가 50% 이상 빠르며, 경쟁 x86 프로세서(AMD EPYC) 대비 벡터 데이터베이스 워크로드에서 최대 70% 높은 성능을 발휘합니다. 양사는 이러한 성능 개선이 코딩 에이전트 및 유사 애플리케이션의 엔드투엔드 개발 주기를 대폭 단축할 것으로 기대하고 있습니다. 나아가 이 공동 제작 준비 완료형 이기종 추론 아키텍처의 가장 큰 장점은 SambaNova SN50과 Xeon 기반 서버가 대다수의 기업 데이터 센터가 지원하는 30kW급 환경에서 드롭인 호환(drop-in compatible)을 이룬다는 점입니다. Intel Corporation의 데이터 센터 그룹(DCG) 총괄 부사장 겸 전무인 Kevork Kechichian은 "데이터 센터 소프트웨어 생태계는 x86을 기반으로 하며 Xeon에서 구동됩니다. 이는 개발자, 기업, 클라우드 공급자가 대규모로 의존하는 성숙하고 검증된 기반을 제공합니다"라고 말했습니다. 그는 이어 "미래 워크로드는 이기종 컴퓨팅의 조합을 요구할 것이며, SambaNova와의 이번 협력은 고객의 요구를 대규모로 충족시키기 위해 설계된, 비용 효율적이고 고성능의 추론 아키텍처를 Xeon 6을 통해 제공할 것입니다"라고 덧붙였습니다.
최신 뉴스와 분석, 리뷰를 피드에서 받아보려면 Google News에서 Tom's Hardware를 팔로우하거나 선호 출처로 추가하세요.