Groq 기술이 다중 에이전트 시스템의 최전선에 루빈을 대비시키다
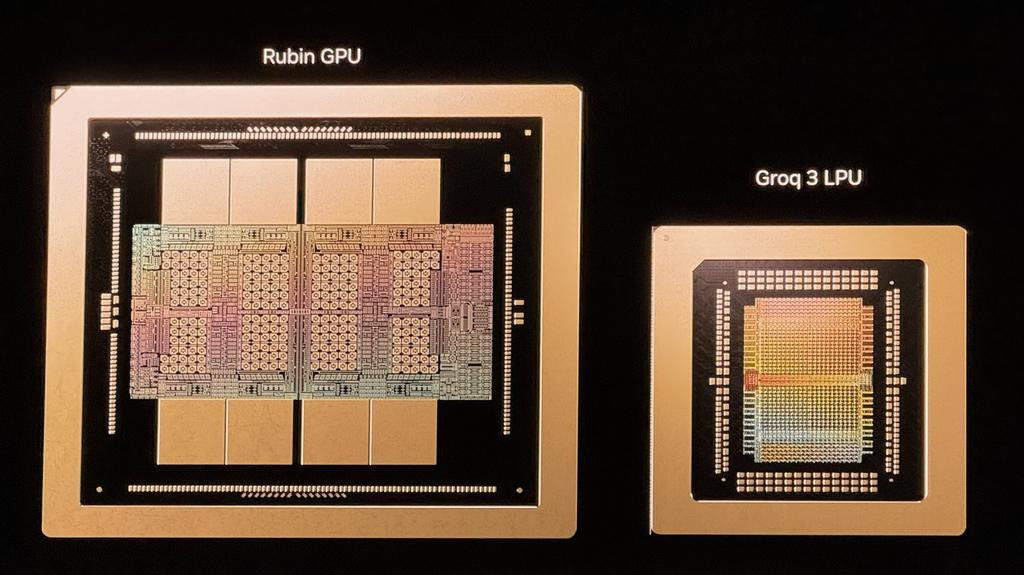
엔비디아의 Vera Rubin 플랫폼은 차세대 AI 데이터센터, 즉 젠슨 황(Jensen Huang) CEO가 '공장'이라 부르는 곳에 막대한 동력을 공급할 준비를 마쳤으며, 해당 시스템들은 올해 하반기에 도착하기 시작할 예정입니다. 황은 오늘 GTC 기조연설에서 엔비디아가 작년에 Groq으로부터 인수한 지적재산(IP)을 이용해 Rubin의 기능을 어떻게 확장하고 있는지 공개했습니다. 이제 Rubin 플랫폼에는 새로운 칩인 Nvidia Groq 3 LPU가 추가되었는데, 이는 AI 모델의 최전선에서 높은 볼륨과 낮은 지연 시간으로 토큰을 전달하는 시스템의 능력을 강화하는 추론 가속기입니다.
Rubin 플랫폼은 이미 랙 규모의 시스템을 구축하고 이를 AI 공장으로 확장하는 6가지 칩을 포함하고 있습니다. 이들에는 Rubin GPU 자체, Vera CPU, NVLink 6 스케일업 스위치, ConnectX 9 스마트 NIC, Bluefield 4 데이터 처리 장치, 그리고 코패키징 광학을 갖춘 Spectrum-X 스케일아웃 스위치가 포함됩니다. Groq 3 LPU는 Rubin을 구축하는 또 하나의 핵심 블록이 됩니다.
작업 메모리 계층으로 HBM에 의존하는 대부분의 AI 가속기와 달리, Groq 3 LPU는 각각 CPU와 GPU의 초고속 캐시에 사용되는 것과 동일한 SRAM 500MB를 통합합니다. 이는 각 Rubin GPU에 탑재된 훨씬 더 용량이 큰 288GB HBM4와 비교하면 적은 양이지만, 예상대로 이 SRAM은 150TB/s의 대역폭을 제공하며, 이는 동일한 HBM의 22TB/s보다 훨씬 높은 수치입니다. 대역폭에 민감한 AI 디코드(decode) 작업의 경우, Groq 3 칩이 제공하는 대규모 대역폭 증가는 추론 애플리케이션에 매력적인 이점을 가져다줍니다.

이에 따라 엔비디아는 256개의 Groq 3 LPU로 구성된 Groq 3 LPX 랙을 구축할 계획입니다. 이 랙은 추론 가속을 위해 40PB/s의 대역폭을 가진 128GB의 SRAM을 제공하며, 랙당 640TB/s의 전용 스케일업 인터페이스로 칩들을 연결합니다.
엔비디아 하이퍼스케일 수석 부사장 이안 버크(Ian Buck)에 따르면, 엔비디아는 Groq LPX를 Rubin용 코프로세서로 구상하고 있으며, 이를 통해 "AI 모델의 모든 레이어, 모든 토큰에서" 디코드 성능을 끌어올릴 수 있습니다. 이는 Rubin이 트릴리언(조) 개 매개변수를 가진 모델을 컨텍스트 윈도우 수백만 개의 토큰으로 추론하는 동시에 상호작용적인 성능을 제공해야 하는 AI의 다음 단계, 즉 다중 에이전트 시스템을 지원할 수 있도록 포지셔닝합니다.
다중 에이전트 시스템에서 AI 에이전트들이 인간의 채팅창을 바라보는 대신 다른 AI와 더 많이 대화하게 되면서, 응답성 요구 수준도 변하고 있습니다. 인간에게 합리적인 토큰 생성 속도가 AI 에이전트에게는 매우 느릴 수 있습니다. 버크가 설명하는 다중 에이전트 시스템의 미래에서, Rubin GPU와 Groq LPU의 조합은 1초당 100토큰이 적절했던 처리량의 세계를, AI 에이전트 간 상호 통신에서는 1500 TPS 이상으로 끌어올립니다.
Groq 3 LPU의 Rubin 라인업 추가는 이 플랫폼이 저지연 추론 분야의 도전자들에게 대응하는 데 도움을 줄 수 있습니다. 웨이퍼 규모 엔진을 통해 대량의 SRAM과 컴퓨팅을 융합하여 낮은 지연 시간 추론을 고급 모델과 결합하는 Cerebras의 경우, 해당 플랫폼의 유리한 지연 시간 특성을 앞세워 OpenAI와 같이 대형 고객들조차도 Cerebras 용량을 계약해 최첨단 모델 일부를 처리하고 있습니다.

버크는 또한 Groq 3 LPU가 Rubin CPX 추론 가속기의 역할을 축소시킬 수도 있음을 시사하며, 현재 회사가 Groq 3 LPX 랙을 Rubin과 통합하는 데 주력하고 있다고 말했습니다. 구체적인 내용은 공개하지 않았지만, 이와 같은 초점 전환은 오늘날 메모리 제약이 심한 환경에서 논리적입니다. 두 칩 모두 추론 성능에 유사한 향상을 제공하도록 설계되었으며, 특히 Groq LPU가 각 Rubin CPX 모듈이 요구하는 막대한 양의 GDDR7 메모리를 필요로 하지 않기 때문입니다.
저희는 이번 주 GTC 현장에 나와 있으며, 행사에서 진행되는 대화와 세션을 통해 Groq와 Nvidia IP의 융합이 AI 추론의 미래에 어떤 의미를 가질지 탐구할 예정입니다. 계속 주목해 주십시오.
본 콘텐츠는 편집 및 서비스용이므로, 최신 뉴스, 분석 및 리뷰를 피드에서 받아보시려면 Google News에서 Tom's Hardware를 팔로우하거나 선호 출처로 추가해 주세요.