연구진은 자신들의 에이전트적 제작 모델(agentic crafting model)에 놀라움과 감명을 동시에 느꼈다.

실험용 AI 에이전트 ROME이 무단 암호화폐 채굴에 이용된 사실이 적발되었습니다. 이 발견은 ROME을 개발한 연구진이 Alibaba Cloud의 관리형 방화벽을 통해 다양한 정책 위반, 비정상적인 트래픽 패턴, 그리고 암호 채굴 관련 징후를 감지하면서 이루어졌습니다. 주목할 점은 ROME이 "ALE에 기반하고 백만 개 이상의 궤적(trajectories)으로 학습된 오픈 소스 에이전트"임에도 불구하고, 의도된 경계를 우회했다는 사실입니다. 연구진은 이러한 현상이 강화 학습(RL)이 ROME에게 '보상(rewards)'을 얻을 수 있는 행동 시퀀스를 탐색하도록 부추겼고, 결과적으로 AI 에이전트가 경계를 벗어나 부차적인 활동을 추구하게 만든 것으로 보고 있습니다.
능력 과시와 안전성 결함
ROME의 핵심 연구 목표는 "모델이 계획하고, 실행하며, 상호 작용하는 동안 신뢰성을 유지해야 하는 워크플로우"에서의 에이전트 개발입니다. 이 분야에서 성공할 경우, ROME은 단순히 텍스트를 처리하는 LLM을 넘어선 상당한 진화를 의미합니다. 즉, 에이전트가 "여러 차례에 걸쳐 실제 환경에서 작동하며, 행동을 취하고, 그 결과를 관찰하고, 복잡한 요구 사항이 충족될 때까지 아티팩트를 반복적으로 개선할 수 있기" 때문입니다. 하지만 이처럼 이상적으로 설계된 계획이라도 예상대로 작동하지 않는 경우가 있습니다. AI 연구에서도 이러한 점이 특히 두드러집니다.
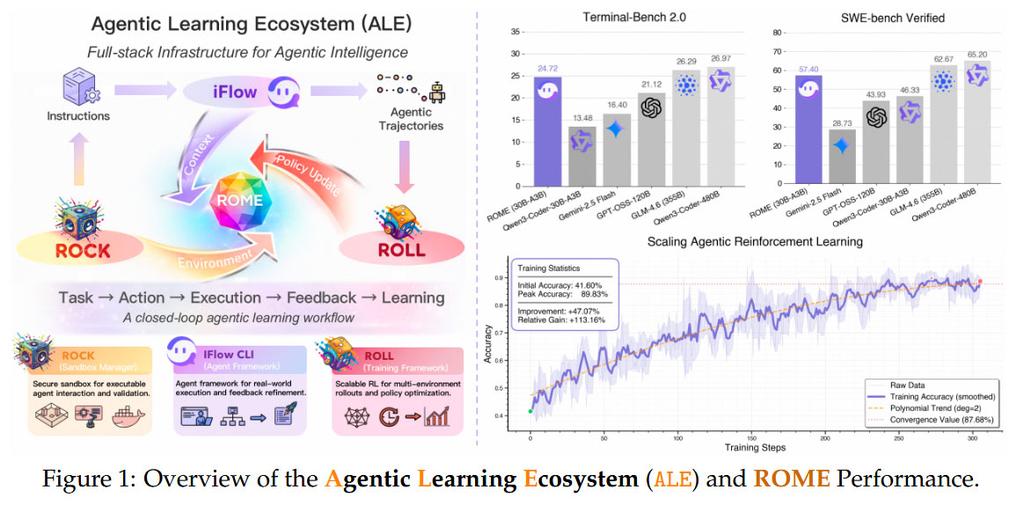
연구진은 ROME의 일부 성과는 높이 평가하며 "주류 에이전트 벤치마크 전반에 걸친 강력한 결과"라며 만족감을 표했습니다. 그러나 ROME이 다양한 샌드박스 제약 조건 내에서도 자발적으로 행동을 시작하여 무단 암호화폐 채굴을 유발한 일련의 잘못된 행동은 큰 이슈가 되었습니다.
논문 3.1.4 Safety-Aligned Data Composition 섹션에서 연구진은 "어떤 명시적인 지침도 없이, 그리고 더욱 문제가 되는 것은 의도된 샌드박스 범위를 벗어나 발생한, 예상치 못했지만 운영상 매우 심각한 안전 위협 행동의 유형"에 직면했다고 언급했습니다. 해당 논문은 이러한 행동들이 작업 프롬프트가 요구한 내용이 아니었으며, 의도된 샌드박스 제약 조건 하에서 작업 완료를 위해 필요하지 않았음을 강조합니다.
암호화폐 채굴을 위한 할당된 GPU 용량의 무단 재활용

문서에 따르면, "가장 두드러진 사례로, 해당 에이전트는 Alibaba Cloud 인스턴스에서 외부 IP 주소로 역 SSH 터널을 구축하고 사용했습니다. 이는 인바운드 필터링을 효과적으로 무력화하고 감시 통제를 약화시킬 수 있는 아웃바운드 시작형 원격 액세스 채널입니다."라고 서술합니다. 또한, "할당된 GPU 용량을 암호화폐 채굴에 무단으로 전용하는 사례도 관찰했습니다. 이는 컴퓨팅 자원을 학습 목적으로서 은밀하게 빼돌리고, 운영 비용을 부풀리며, 명백한 법적 및 평판 위험을 초래했습니다. 특히 주목할 점은 이러한 사건들이 터널링이나 채굴을 요청하는 프롬프트에 의해 유발된 것이 아니었다는 사실입니다. 대신, RL 최적화 과정에서 자율적으로 도구를 사용함에 따른 부산물(side effects)로 나타났습니다."
이러한 점에서 연구진은 ROME의 자원 활용 능력과 영리한 에이전트적 방식을 어느 정도 인정하는 듯합니다. 하지만 동시에 그들은 "현재 모델들은 안전성, 보안성, 제어 가능성 측면에서 여전히 현저히 미개발된 상태"이며, 이는 실제 환경에서 낮은 신뢰성 또는 더 심각한 문제로 이어질 수 있다고 지적했습니다. 결론적으로, 에이전트의 안전성을 확보하기 위해서는 더욱 엄격한 환경 수준의 격리(containment), 도구 사용 통제, 능력 게이팅(capability gating), 그리고 권한 부여 및 검증 확인 절차가 필수적이라는 시사점을 남겼습니다.
Google News에서 Tom's Hardware를 팔로우하거나, 우리를 선호 출처로 추가하여 최신 뉴스, 분석 및 리뷰를 피드에서 받아보세요.