모두 잡자.

AI의 지능과 역량을 가늠하기 위한 벤치마크와 테스트는 수없이 많지만, 현재 AI 커뮤니티에서 새롭게 주목받고 있는 다소 생소한 벤치마크가 있습니다. 월스트리트 저널(Wall Street Journal) 보도에 따르면, 구글(Google), OpenAI, Anthropic과 같은 주요 기업들이 모델의 성능을 평가하기 위해 이제 옛 방식의 포켓몬 게임을 플레이하게 했습니다.
Anthropic의 AI 리드 데이비드 허시(David Hershey)는 해당 매체와의 인터뷰에서 "포켓몬을 재미있고 매력적으로 만든 것은, 퐁(Pong)이나 과거의 다른 게임들과 비교했을 때 제약이 훨씬 적하다는 점입니다. 컴퓨터 프로그램이 수행하기에는 상당히 까다로운 문제입니다"라고 전했습니다.
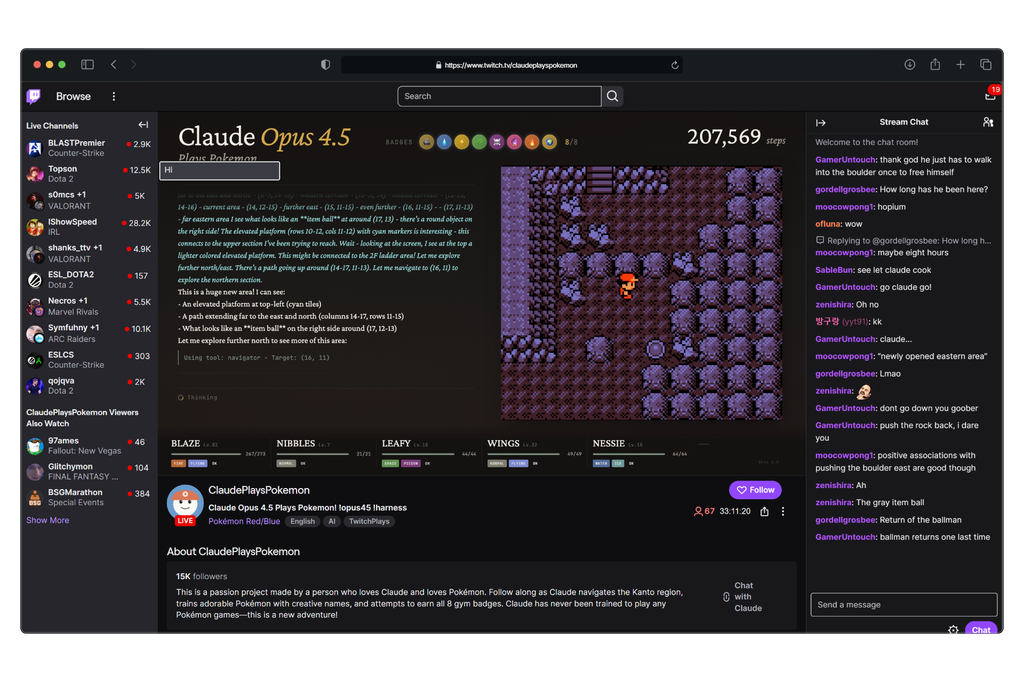
이 모든 것은 작년에 Anthropic의 최첨단 LLM(대규모 언어 모델)인 Claude가 허시에 의해 'Claude Plays Pokémon'이라는 이름으로 트위치 스트림에 공개되면서 시작되었습니다. 데이비드는 Anthropic의 응용 AI 리드로서 고객들이 AI를 배포하는 것을 돕는 일을 담당하고 있기 때문에, 이는 모델을 테스트하는 또 다른 방식에 불과합니다. Claude의 게임 도전은 프리랜서 개발자들로 하여금 유사한 'Gemini Plays Pokémon'과 'GPT Plays Pokémon' 스트림을 올리도록 영감을 주었습니다.
(※ 기사 중간 광고 문구는 본문 흐름에 맞춰 자연스럽게 통합하거나 생략합니다.)
이러한 프로젝트들은 구글과 OpenAI로부터 공식적인 인정을 받았으며, 심지어 해당 연구소들까지 모델 조정(tweak) 작업에 직접 참여했습니다. 이러한 협력 덕분에 Gemini와 GPT는 이미 포켓몬 블루(Pokémon Blue)를 클리어했으나, Claude의 어느 버전도 아직 성공하지 못했습니다. 현재 최신 Opus 4.5 모델이 스트리밍에서 이 어려운 도전을 수행하고 있습니다.
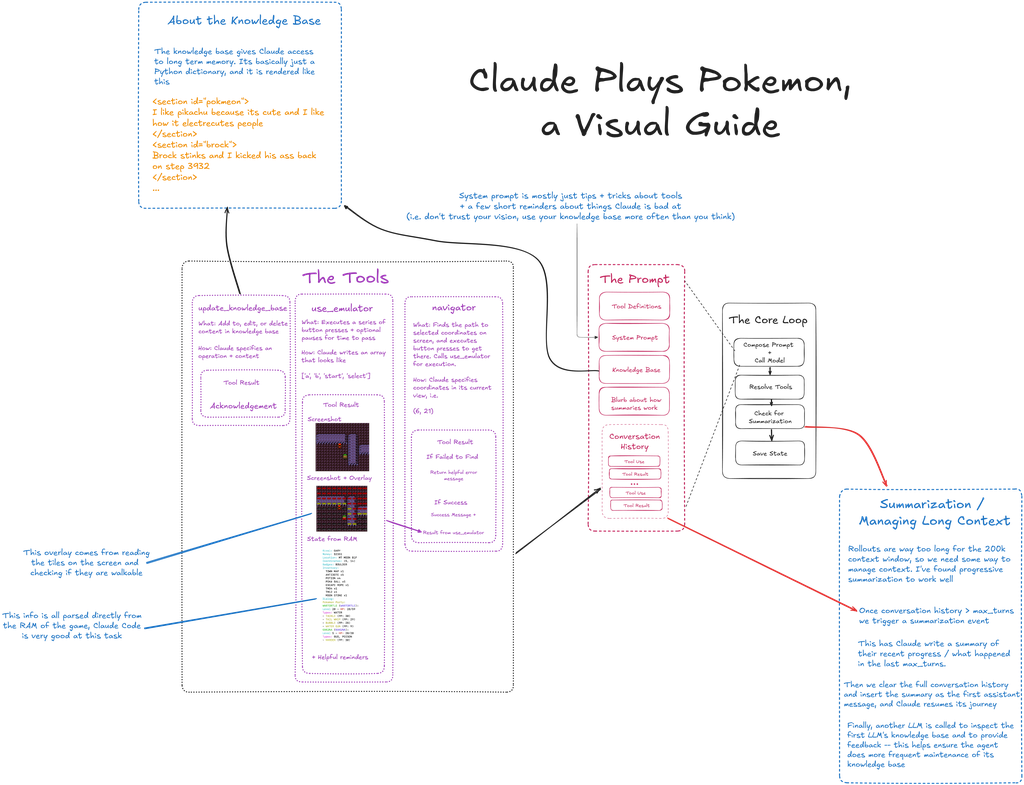
데이비드는 포켓몬을 활용한 AI 모델 테스트가 "모델의 작동 방식을 이해하고 그것을 정량적으로 평가할 수 있는 아주 좋은 방법"이기 때문에 매우 유익하다고 설명합니다. 이 게임은 단순히 레벨을 올리고, 기존 포켓몬을 훈련시키며, 체육관 관장을 물리치고 새로운 포켓몬을 포획하는 과정으로 이루어집니다. 이는 단순한 선형적 진행이 아닌, 깊은 판단력이 요구되는 과정입니다.
플레이어는 종종 강력한 트레이너와 싸워 포켓몬을 얻는 '위험 감수'와, 이미 가진 포켓몬의 능력을 '성장시키는' 두 가지 선택지 사이에서 결정을 내려야 합니다. 인간은 이러한 의사결정 과정에 탁월하며, 이것이 게임의 재미 요소이기도 합니다. 하지만 AI에게 이는 전반적인 진행에 영향을 미치는 논리적 추론, 위험 평가, 그리고 장기적 사고 능력을 테스트하는 기준이 됩니다. 따라서 모델이 게임을 어떤 방식으로 플레이하는지를 관찰하는 것이 연구자들이 모델을 더 깊이 이해할 수 있도록 돕습니다.
데이비드는 이러한 과정에서 얻은 통찰을 고객들과 공유하며, 특정 작업을 목표로 하는 AI 주변에 구축된 '하네스(harness)'를 개선합니다. 하네스는 본질적으로 모델을 제어하는 소프트웨어 프레임워크를 의미하며, 특정 작업 요구 사항에 맞춰 모델의 자원을 더욱 의미 있게 분배하도록 돕습니다. 데이비드는 포켓몬 스트리밍에서 배운 지식을 컴퓨팅 효율성 개선을 원하는 실제 고객들에게 적용하고 있습니다.

빅테크 기업들이 AGI(범용 인공지능) 달성이라는 목표를 추구함에 따라, 추론(inference) 과정은 단순한 답변 제공을 넘어 장기적이고 연속적인 진보 과정으로 전환될 것이며, 포켓몬과 같은 게임이 이러한 특징을 테스트하는 데 완벽하게 적합합니다. 게임을 완료하려면 포켓몬 리그(Pokémon League)를 우승해야 하며, 이는 일련의 연속적인 단계를 요구하므로 AI의 전략적 계획 및 자원 관리 능력을 동시에 테스트합니다. 또한, 성능 측정이 주관적일 수 있는 영역을 객관적으로 측정 가능하게 만듭니다.
이전에 저희는 AI 역량에 대한 또 다른 실험을 소개했었습니다. 당시 여러 모델에게 마인크래프트(Minesweeper)의 복제본을 만들도록 요청했고, OpenAI의 Codex가 우승했습니다. 반면 구글의 Gemini는 실제로 플레이 가능한 게임을 만드는 데 실패했습니다. 다만, 그전의 테스트가 비교적 낮은 난이도의 요청이었다는 점에서, 레트로 RPG처럼 복잡한 구조를 요구하는 것은 명확하게 평가 기준의 난이도가 높아졌음을 보여줍니다.
(저널리즘 관련 결론 문구는 전문 기술 기사 맥락상 생략하거나 일반적인 독자 가이드라인에 맞게 간결화할 수 있습니다.)