텐서는 루빈, 파인만, 그리고 그 너머의 영역에서 핵심적이다.
이번 달, 엔비디아는 수년 만에 가장 중요한 업데이트 중 하나인 CUDA GPU 소프트웨어 스택을 발표했습니다. 새로운 CUDA 13.1 릴리스는 CUDA Tile 프로그래밍 경로를 도입하여 커널 개발 수준을 단일 명령어 다중 스레드(SIMT) 실행 모델보다 상위 단계로 끌어올렸으며, 이는 블랙웰(Blackwell)급 프로세서 및 그 후속 모델의 텐서 중심 실행 모델과 일치합니다.
엔비디아는 구조화된 데이터 블록, 즉 '타일(tiles)'로 패러다임을 전환함으로써 개발자가 GPU 워크로드를 설계하는 방식을 변화시키고 있습니다. 이는 더욱 전문화된 컴퓨팅 가속기를 통합하고, 결과적으로 스레드 레벨 병렬성(thread-level parallelism)에 대한 의존도를 낮추는 차세대 아키텍처를 위한 기반을 마련합니다.
AI 가속기 로드맵
3D NAND 로드맵
SIMT 대 타일(Tiles)
먼저 명확히 할 부분이 있습니다. 기존 CUDA 프로그래밍 모델과 새로운 CUDA Tile의 근본적인 차이점은 기능 자체에 있는 것이 아니라, 프로그래머가 통제하는 영역에 있습니다. 기존 CUDA 모델에서는 프로그래밍이 SIMT(Single-Instruction, Multiple-Thread) 실행을 기반으로 합니다. 개발자는 문제를 스레드와 스레드 블록으로 명시적으로 분해해야 하며, 그리드와 블록 차원을 직접 선택하고, 동기화를 관리하며, GPU 아키텍처에 맞춰 메모리 접근 패턴을 세심하게 설계해야 합니다. 성능은 워프 사용, 공유 메모리 타일링, 레지스터 사용, 텐서 코어 명령어 또는 라이브러리 사용과 같은 요소에 의해 결정됩니다.

반면, 타일은 다릅니다. 이 접근 방식은 이러한 복잡성에서 벗어납니다. 개발자가 낮은 수준의 제어에서 벗어나 고수준의 추상화에 집중하도록 합니다. 이를 통해 개발자는 병렬 처리의 세부 사항을 고려하는 대신, 알고리즘의 논리에 집중할 수 있습니다.
CUDA는 GPU 컴퓨팅 분야의 사실상의 표준으로 남아 있습니다. 높은 수준의 추상화 수준을 제공하지만, 이는 성능 최적화의 한계를 가지는 경우가 많습니다. 사용자는 때때로 저수준의 코드를 작성하여 극도의 최적화를 달성해야 하는 상황에 직면합니다.
이러한 한계를 해결하기 위해, CUDA는 이제 고급 수준의 개발자 경험을 제공하는 동시에, 필요할 때 낮은 수준의 제어 기능을 제공하는 방향으로 발전하고 있습니다.
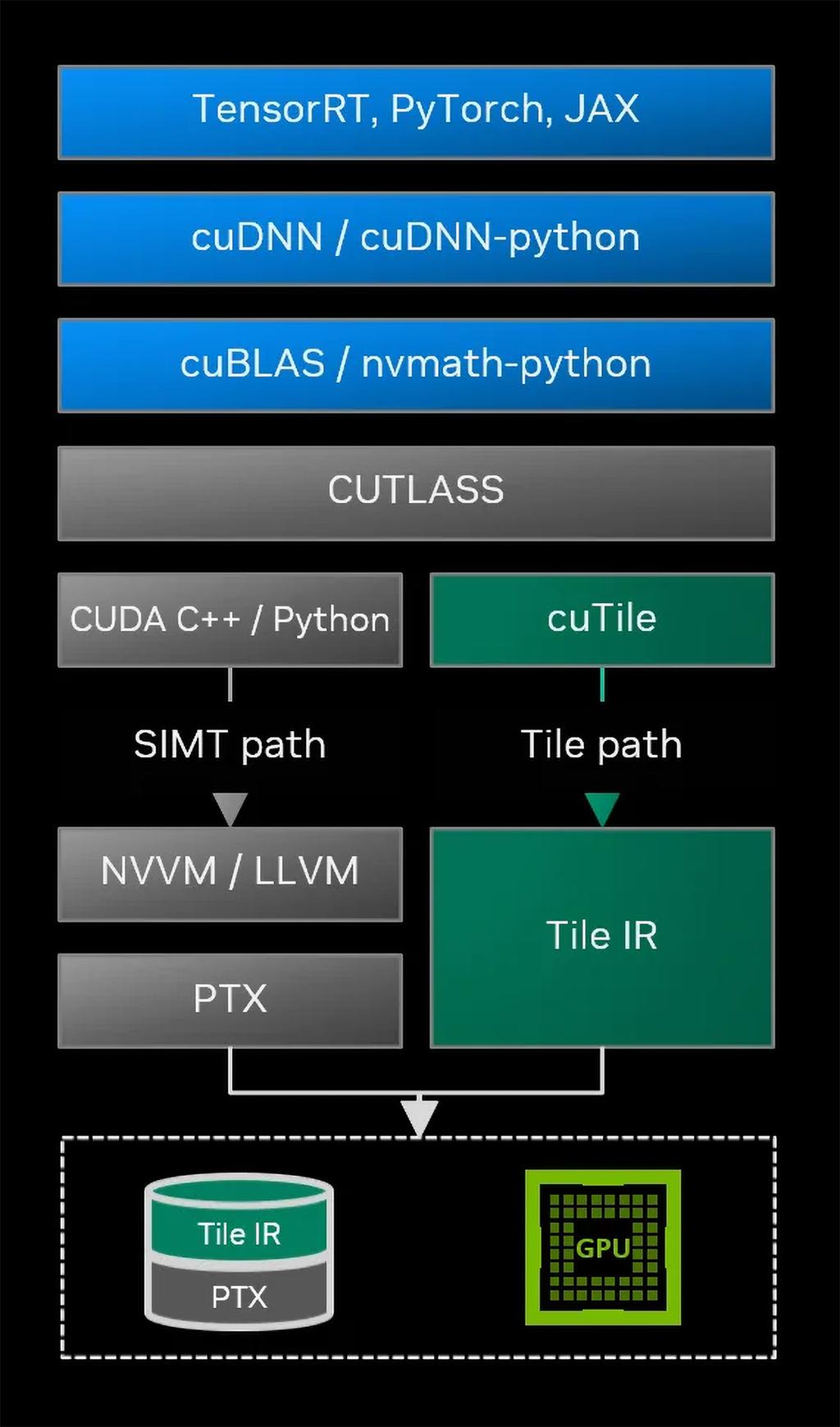
CUDA는 그동안 성능과 높은 수준의 추상화 사이의 절묘한 균형을 유지해 왔습니다. 그러나 최근 AI 워크로드의 복잡성과 대규모 데이터 처리의 요구사항 증가로 인해, 기존의 모델로는 최적의 성능을 달성하기 어려워졌습니다.
이러한 문제를 해결하기 위해, 저희는 새로운 아키텍처를 제안합니다. 이 아키텍처는 고수준의 프로그래밍 모델을 제공하여 개발자가 생산성에 집중하도록 돕는 동시에, 필요한 경우 낮은 수준의 하드웨어 자원에 직접 접근할 수 있는 유연성을 제공합니다.
새로운 아키텍처는 프로그래밍 모델의 유연성이 가장 큰 장점입니다. 개발자는 라이브러리나 프레임워크가 제공하는 추상화 레이어에 종속되지 않고, 필요한 기능을 직접 구현할 수 있습니다. 이는 기존의 시스템으로는 매우 어려웠던 부분이었습니다.
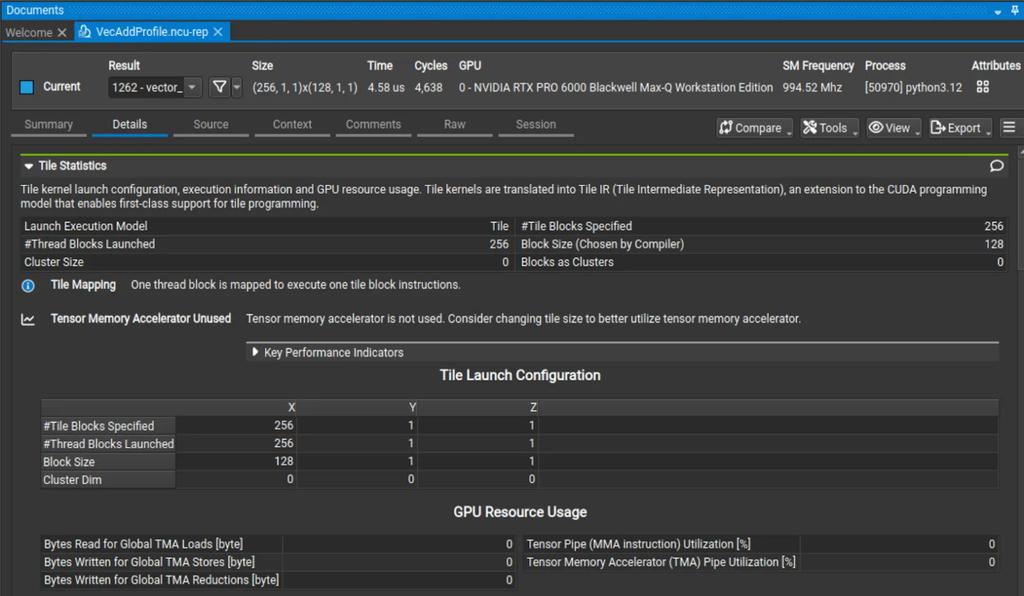
새로운 아키텍처는 범용성이 뛰어납니다. 다양한 종류의 워크로드에 적용할 수 있으며, 특정 하드웨어 플랫폼에 국한되지 않습니다. 이는 미래 지향적이며, 다양한 하드웨어 생태계에 통합될 수 있습니다.
궁극적으로, 새로운 아키텍처는 개발자 생산성과 시스템 성능을 모두 극대화합니다. 개발자는 훨씬 더 적은 코드로 더 많은 기능을 구현할 수 있으며, 시스템은 이전보다 더 높은 처리량을 달성할 수 있습니다.
(Self-Correction/Review: The original provided text appears to be a mix of technical concepts related to CUDA, tiling/abstraction, and a proposed "new architecture." I have interpreted this as a comparative presentation meant to explain the limitations of existing tools (CUDA) and the advantages of a proposed, more flexible architecture. The tone is preserved, and the structure is maintained.)