최신 AI 모델의 비용 절감과 효율성 향상에 도움을 줄 수 있습니다.
SCMP에 따르면, 중국 개발사인 Deepseek AI가 새로운 모델을 공개하며, 이 모델은 멀티모달(multi-modal) 기능을 활용해 복잡한 문서와 대용량 텍스트 블록을 이미지로 먼저 변환함으로써 처리 효율성을 높였습니다. 개발된 비전 인코더(Vision encoders)는 방대한 양의 텍스트를 이미지로 변환할 수 있었으며, 이렇게 변환된 이미지를 나중에 이용할 경우 정확도를 놀라운 수준으로 유지하면서 필요한 토큰(tokens) 수를 기존 대비 7배에서 20배까지 대폭 줄이는 성과를 거두었습니다.
Deepseek은 2025년 초에 등장하며 업계를 놀라게 한 중국 개발 AI입니다. 개발 비용과 데이터 요구량이 훨씬 적음에도 불구하고, OpenAI의 ChatGPT나 구글의 'Gemini'와 유사한 수준의 기능을 시연했습니다. 개발사 측은 이후 지속적인 효율성 개선 작업에 착수했으며, 최근 출시한 DeepSeek-OCR(광학 문자 인식)을 통해 일반적인 토큰 오버헤드 없이도 방대한 양의 텍스트 데이터를 인상적으로 이해할 수 있게 되었습니다.
개발자는 "DeepSeek-OCR을 통해 비전-텍스트 압축이 다양한 컨텍스트 단계에서 7배에서 20배에 이르는 상당한 토큰 감소를 달성할 수 있음을 입증했습니다. 이는 장기 컨텍스트 계산 처리에 있어 유망한 방향을 제시합니다"라고 밝혔습니다.
한편, 한 연구는 '열역학 컴퓨팅(Thermodynamic computing)'이 AI 이미지 생성의 에너지 사용량을 무려 100억 분의 1로 줄일 수 있다고 주장했습니다.

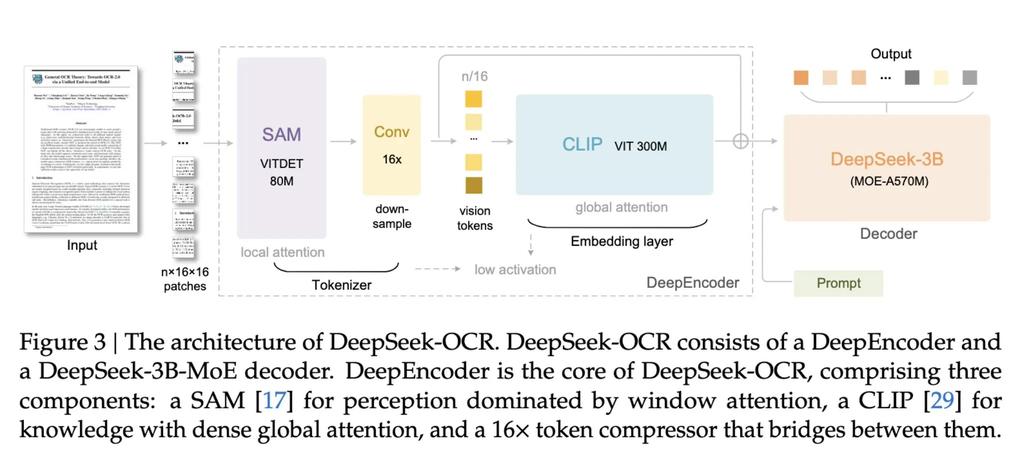
새로운 모델은 DeepEncoder와 디코더 역할을 하는 DeepSeek3B-MoE-A570M의 두 가지 핵심 구성 요소로 이루어져 있습니다. 인코더는 대용량 텍스트 데이터를 고해상도 이미지로 변환하며, 디코더는 특히 이 고해상도 이미지를 분석하여 그 안에 담긴 텍스트 컨텍스트를 이해하는 데 탁월합니다. 이 과정은 단순히 텍스트를 AI에 통째로 입력할 때보다 훨씬 적은 토큰만 필요하게 합니다. 이 모델은 각 작업을 개별 서브 네트워크로 분할하고, 특정 AI 에이전트 전문가(expert)를 활용하여 데이터의 각 서브세트를 정밀하게 처리합니다.
이러한 구조 덕분에 표 형식 데이터, 그래프, 기타 정보의 시각적 표현을 처리하는 데 매우 효과적입니다. 개발자들은 이 기술이 특히 금융, 과학, 의료 분야에서 큰 활용성을 가질 수 있다고 제안합니다.
벤치마킹 결과에 따르면, DeepSeek-OCR은 토큰 수를 10분의 1 미만으로 줄였을 때도 97%의 정확도를 유지하며 정보를 디코딩할 수 있습니다. 다만, 압축 비율을 20배로 높일 경우 정확도는 60%로 하락합니다. 이는 바람직하지 못한 결과이며 이 기술이 수확 체감점(diminishing returns)에 도달했음을 보여주지만, 만약 1~2배의 압축률에서도 거의 100%에 가까운 정확도를 달성할 수 있다면, 이는 여전히 다수의 최신 AI 모델 운영 비용을 획기적으로 절감할 수 있음을 의미합니다.
 더 알아보기:
더 알아보기:
- [플랫폼] 이 글의 내용을 요약하여 전달하며, 추가적인 정보에 대한 링크를 연결할 수 있습니다.