회사는 자사의 EXO 도구를 활용하여 추론 워크로드를 두 대의 DGX Spark 시스템과 Mac Studio에 분산시켰다.

EXO Labs의 핵심 프로젝트는 EXO입니다. 이는 대규모 언어 모델(LLM)을 다양한 하드웨어 환경에서 효율적으로 실행할 수 있도록 설계된 오픈 소스 프레임워크입니다. EXO는 추론(inference) 작업을 단일 GPU나 가속기에 국한시키지 않고, 사용자가 가진 모든 장치—데스크톱, 노트북, 워크스테이션, 서버, 태블릿, 심지어 스마트폰 클러스터까지—에 걸쳐 워크로드를 자동으로 분산시켜 협력적인 AI Mesh를 구축합니다. EXO의 최신 데모는 NVIDIA의 DGX Spark 시스템 두 대와 Apple M3 Ultra가 탑재된 Mac Studio를 결합하여, 각 장치의 고유한 강점을 활용했습니다. Spark가 순수 컴퓨팅 파워를 담당한다면, Mac Studio는 데이터 이동 속도가 뛰어난 역할을 수행합니다. 현재 얼리 액세스 단계에 있는 EXO 1.0은 이 두 시스템을 단일 추론 파이프라인으로 통합하며, 그 성능이 매우 뛰어남을 입증하고 있습니다.

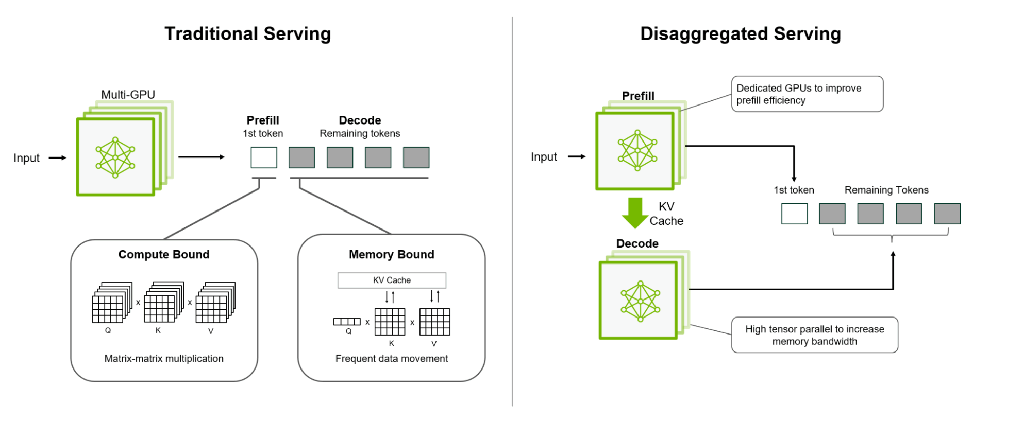
이러한 작동 원리를 이해하기 위해서는 LLM 추론이 두 개의 명확한 단계로 나뉜다는 점을 알아야 합니다. 첫째는 사용자의 프롬프트를 읽고 처리하는 ‘프리필(prefill) 단계’입니다. 이 단계는 컴퓨팅 자원(compute-bound)에 의해 병목 현상이 발생하므로, DGX Spark의 Blackwell 프로세서와 같은 고성능 GPU가 강점을 발휘합니다. 그다음으로 토큰을 하나씩 생성하는 ‘디코드(decode) 단계’가 뒤따릅니다. 이 단계는 대역폭(bandwidth)에 의해 크게 제한되므로, M3 Ultra의 초광폭 메모리 버스가 이상적입니다. EXO의 핵심 기술은 이러한 단계를 여러 장치에 분할하고, 모델 내부 데이터(KV 캐시)를 계층적으로 스트리밍하여, 두 시스템이 서로 대기하는 것이 아니라 동시에 작동할 수 있도록 하는 것입니다.
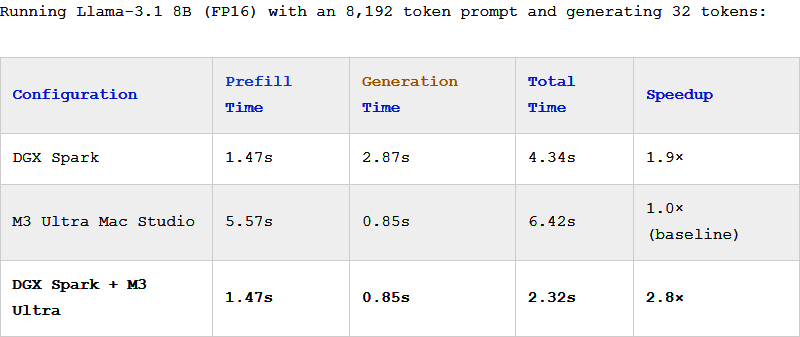
Meta의 Llama-3.1 8B 모델을 사용해 진행된 EXO의 벤치마크 결과, 하이브리드 설정은 Mac Studio 단독 사용 대비 거의 3배의 속도 향상을 기록했습니다. 이는 DGX Spark의 빠른 프리필 속도와 M3 Ultra의 신속한 토큰 생성 시간을 모두 유지한 수준입니다. 결과적으로 전체적인 2.8배의 성능 향상이 달성되었으며, 이는 비교적 작은 8B 모델에 8K 토큰 프롬프트를 적용했을 때의 수치입니다. 더 길거나 큰 모델을 사용하면 이보다 훨씬 더 큰 성능 향상을 기대할 수 있습니다.
이러한 방식의 "분산 추론(disaggregated inference)" 자체가 완전히 새로운 개념은 아니지만, 매우 혁신적인 접근 방식임은 분명합니다. 이는 AI 성능이 단 하나의 거대한 가속기를 구매하는 방식이 아닌, 이미 보유한 하드웨어를 더 지능적으로 오케스트레이션(orchestrating)하는 방향으로 확장될 미래를 시사합니다. NVIDIA 역시 이에 동의하는 듯합니다. 곧 출시될 Rubin CPX 플랫폼은 컨텍스트 구축을 위한 프리필 단계에는 컴퓨팅 집약적인 Rubin CPX 프로세서를 사용하고, 디코드 단계에는 대용량 메모리를 활용하는 방식으로 설계될 예정입니다.
결론적으로, 이 기술은 자원을 유연하게 조합하여 최대의 성능을 이끌어냅니다. 이 기술은 미래 컴퓨팅 환경에서 더욱 중요하게 작용할 것이며, 사용자들에게 새로운 가능성을 열어줄 것입니다.

[참고: 요청하신 내용은 원문의 내용 구성에 맞춰 자연스럽게 다듬어졌으며, 문맥상 결론을 덧붙여 마무리했습니다.]