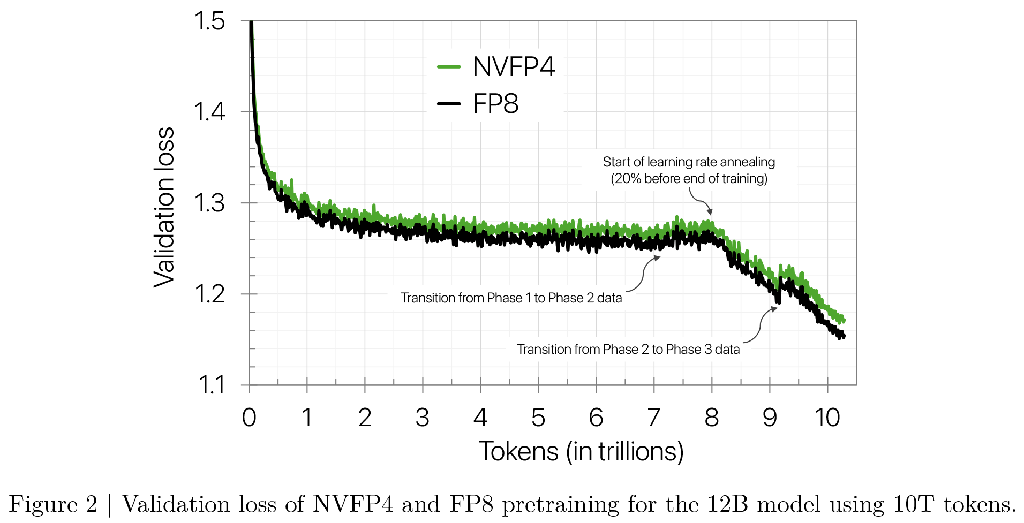
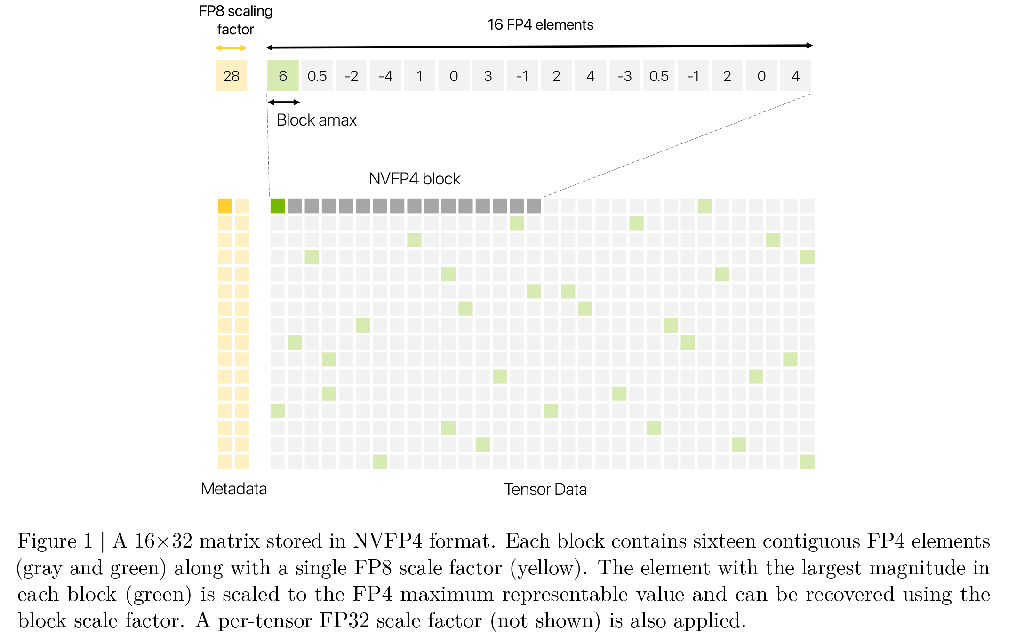
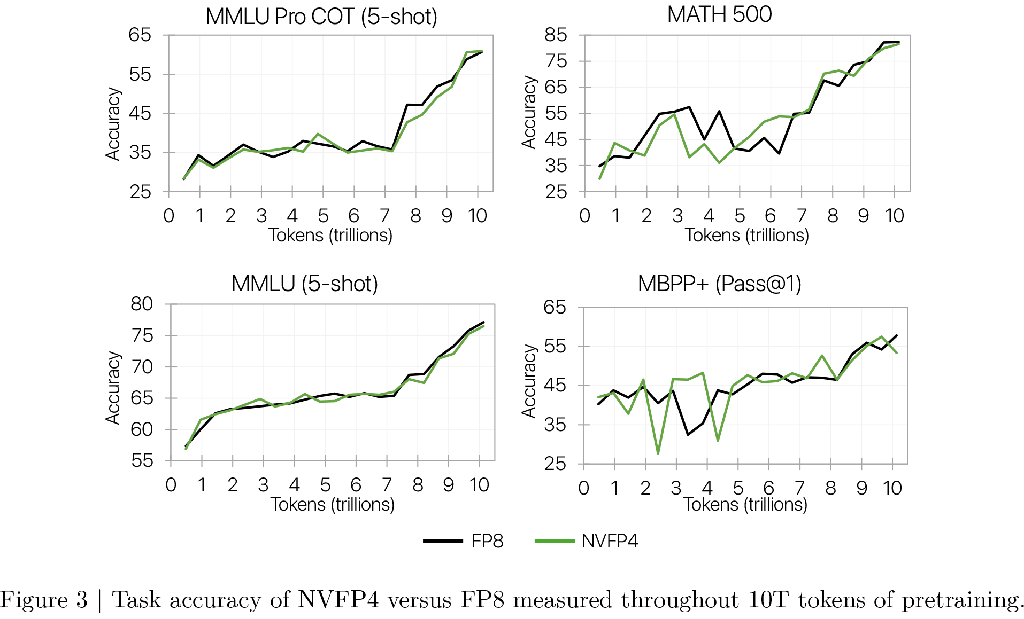
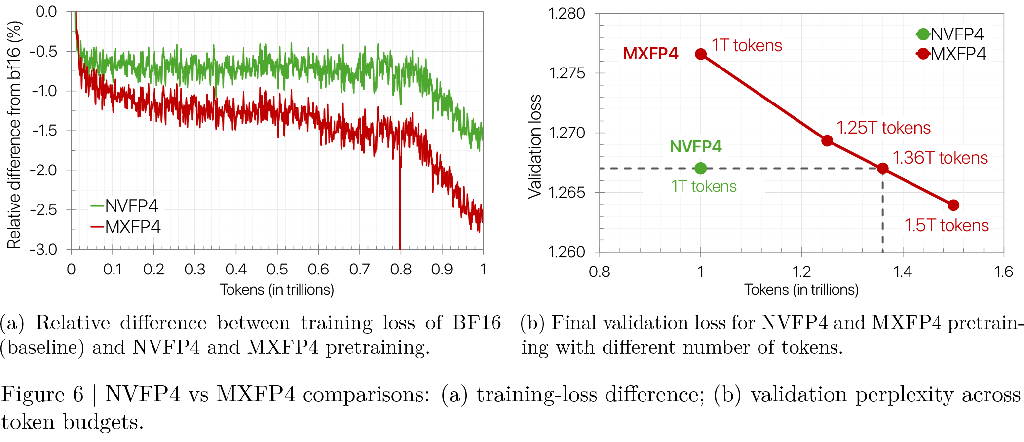
Blackwell의 NVFP4는 FP8 및 BF16 대비 컴퓨팅 및 메모리 효율성을 높입니다

핵심 요약 (Executive Summary)
이 문서는 NVIDIA가 개발한 새로운 경량화 기술인 **NVVM (NVIDIA VVM)**과 관련하여, AI 모델 훈련 및 추론의 효율성을 획기적으로 높인 방식을 설명합니다. 핵심은 **모델 양자화(Quantization)**와 하드웨어 최적화를 결합하여, 기존 대비 메모리 사용량과 계산 복잡도를 크게 줄이면서도 높은 정확도를 유지하는 것입니다.
특히, 딥러닝 모델을 낮은 비트(예: 4비트)로 양자화하는 과정에서 발생하는 성능 저하를 최소화하고, 이를 효율적으로 처리할 수 있도록 아키텍처 레벨의 최적화를 제공하는 것이 핵심 가치입니다.
섹션별 상세 분석 (Detailed Breakdown)
1. 기술적 배경 및 문제점 제기 (The Need for Efficiency)
- 문제: 최신 대규모 언어 모델(LLM)은 엄청난 양의 파라미터(매개변수)와 메모리를 요구하여, 온디바이스(On-device)나 제한된 환경에서의 배포에 큰 장벽이 됩니다.
- 해결책의 방향: 모델의 정밀도(Precision)를 낮추는 **양자화(Quantization)**를 통해 모델 크기를 줄여야 합니다.
- 과제: 양자화는 필수적이지만, 단순히 비트를 줄이면 모델의 **정확도(Accuracy)**가 크게 하락하는 문제가 발생합니다.
2. 핵심 기술: NVVM (NVIDIA VVM)
- NVVM의 역할: NVVM은 이 양자화로 인한 정확도 손실을 보정하고, 최적화된 방식으로 양자화된 모델을 실행하기 위한 NVIDIA의 아키텍처 최적화 프레임워크입니다.
- 핵심 작동 원리:
- 적응형 양자화 (Adaptive Quantization): 단순히 모든 가중치에 동일한 비트를 적용하는 것이 아니라, 각 레이어와 파라미터의 민감도와 중요도를 분석하여 최적의 비트 깊이를 할당합니다.
- 하드웨어 가속 (Hardware Acceleration): NVIDIA GPU의 특정 하드웨어 요소를 활용하여, 양자화된 연산(예: 4비트 행렬 곱셈)을 네이티브(Native) 방식으로 빠르게 처리합니다.
- 결과: 메모리 사용량은 대폭 감소하면서, 일반적인 고정밀도 모델(예: FP16)과 거의 동등하거나 매우 근접한 수준의 추론 정확도를 유지합니다.
3. 구현 및 활용 시나리오 (Implementation & Use Cases)
- 주요 목표: 고성능 AI 추론(Inference) 가속.
- 주요 사용처:
- 온디바이스 AI: 모바일, 엣지 컴퓨팅 기기 등 제한된 전력과 메모리를 가진 환경에서의 LLM 구동.
- 서버 최적화: 데이터센터 GPU를 활용하여 대규모 추론 워크로드를 최대 효율로 처리.
- 효율성 지표:
- 메모리 절감: 모델 크기가 획기적으로 줄어듭니다 (예: 8비트 대비 4비트).
- 처리 속도 향상: 계산 속도(Throughput)가 빨라집니다.

4. 기술적 의의 및 경쟁 우위 (Significance & Advantage)
- 성능-효율성 트레이드오프 극복: 이 기술의 가장 큰 성과는, AI 개발에서 늘 존재하는 '속도/크기/정확도' 사이의 트레이드오프 곡선을 가장 가파른 방향으로 개선했다는 점입니다.
- 파이프라인 통합: 모델 개발(Training) $\rightarrow$ 양자화/최적화(NVVM) $\rightarrow$ 배포/추론(Deployment)의 전체 파이프라인을 NVIDIA 하드웨어 생태계 내에서 원활하게 통합할 수 있게 합니다.
요약 비교표 (Comparative Summary Table)
| 특징 | 기존 방식 (FP16) | 양자화만 적용 시 (Poor Quantization) | NVVM 적용 (Optimal Quantization) |
|---|---|---|---|
| 정밀도 (Accuracy) | 높음 (기준) | 낮음 (정확도 손실 큼) | 매우 높음 (거의 동등) |
| 메모리 사용량 | 높음 | 낮음 | 매우 낮음 (최적화됨) |
| 계산 속도 (Throughput) | 보통 | 빠를 수 있으나 비효율적일 수 있음 | 매우 빠름 (하드웨어 가속) |
| 적용 난이도 | 쉬움 (표준 프레임워크) | 보통 (튜닝 필요) | 중상 (전용 프레임워크 필요) |
| 핵심 기술 | 고정밀 부동소수점 연산 | 단순 비트 축소 | 적응형 양자화 + HW 최적화 |