액셀러레이터를 위한 액셀러레이터.

요약 및 주요 내용 분석
본 문서는 엔비디아(NVIDIA)가 발표한 새로운 컴퓨팅 아키텍처의 핵심 기술인 **루빈(Rubin)**과 이를 활용한 컴퓨팅 가속기 시스템에 대한 심층 분석 기사입니다. 특히, 기존의 AI 가속기들이 직면했던 한계를 극복하고, 대규모 언어 모델(LLM)의 추론(Inference) 효율성을 혁신적으로 개선하는 데 초점을 맞추고 있습니다.
 핵심 기술 요약
핵심 기술 요약
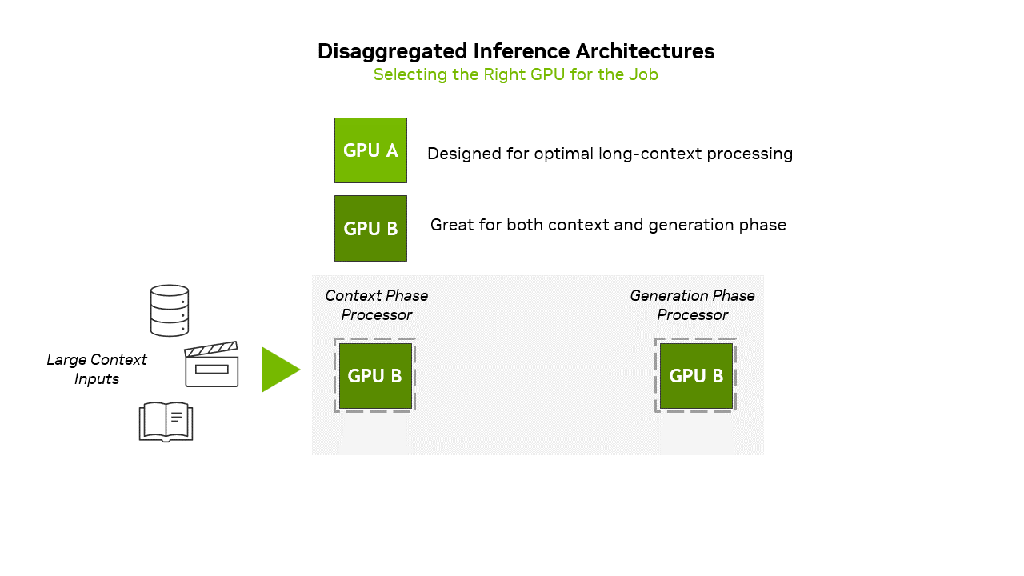
-
루빈(Rubin) 아키텍처:
- 루빈은 차세대 AI 가속기 플랫폼입니다.
- 이 아키텍처의 핵심 목표는 LLM 추론 워크로드의 **전력 효율성(Power Efficiency)**과 **처리량(Throughput)**을 획기적으로 높이는 것입니다.
-
추론 최적화 (Inference Optimization):
- LLM 추론은 학습(Training) 단계보다 전력 효율성이 훨씬 중요한 작업입니다. 루빈은 이 추론 워크로드에 최적화되어 설계되었습니다.
- 핵심 메커니즘: 이를 통해 모델 추론 과정에서 발생하는 불필요한 연산과 전력 낭비를 최소화합니다.
-
메모리 혁신 (Memory Bandwidth):
- LLM의 성능 병목 현상 중 하나는 메모리 대역폭 한계입니다. 루빈은 이 문제를 해결하기 위한 메모리 기술적 진보를 포함합니다.
-
시스템 통합 (System Integration):
- 단순히 칩 성능 향상에 그치지 않고, 토폴로지(Topology) 수준에서의 시스템 통합을 강조합니다. 즉, 칩, 메모리, 네트워킹이 유기적으로 결합되어 전체 시스템의 성능을 극대화합니다.

 주요 특징 및 산업적 시사점
주요 특징 및 산업적 시사점
| 특징/기능 | 설명 | 산업적 의미 |
|---|---|---|
| 추론 최적화 | LLM 추론 단계에 특화되어 전력 대비 성능이 극대화됨. | 데이터센터 및 엣지 디바이스에서 LLM 구동 비용 절감에 결정적 역할. |
| 높은 전력 효율성 | 동급 성능 대비 전력 소모가 현저히 낮아짐. | 운영 비용(OPEX) 절감의 핵심 동인이 되며, 데이터센터 운영 환경에 매우 중요함. |
| 시스템 토폴로지 강조 | 칩 자체 성능뿐만 아니라, 전체 데이터 연결 구조 최적화를 통해 병목 현상을 해결함. | 고성능 컴퓨팅(HPC) 분야에서 시스템 설계의 패러다임 변화를 예고함. |
| 후속 기술 (예: 다음 세대) | 루빈의 성공은 엔비디아가 지속적으로 AI 인프라 시장을 선점하겠다는 의지를 보여줌. | 하이퍼스케일 클라우드 제공업체(CSP)들의 인프라 투자 방향성을 제시함. |

 비유적 설명 (쉽게 이해하기)
비유적 설명 (쉽게 이해하기)
만약 LLM을 **거대한 공장(Factory)**이라고 가정한다면:
- 기존 GPU: 공장의 모든 기계(컴포넌트)를 단순히 강력하게 만드는 것에 집중했습니다. (힘이 세지만, 전기를 많이 쓰고 비효율적일 수 있음.)
- 루빈 아키텍처: 공장 **전체 구조(토폴로지)**를 재설계했습니다. 어떤 부품에 전기를 어떻게, 어떤 순서로 연결해야 가장 적은 에너지로 가장 많은 제품(추론 결과물)을 찍어낼 수 있는지에 초점을 맞춘 것입니다.
결론적으로, 루빈은 '더 강력한 힘'보다는 '더 똑똑하고 효율적인 에너지 사용 방식'을 통해 AI 시장의 핵심 병목인 '추론 비용' 문제를 해결하는 것이 핵심입니다.