고객 AI 성능의 급변하는 환경을 탐색하는 데 유용한 새로운 도구
AI 혁명 시대가 도래했지만, 과거 컴퓨팅 패러다임의 변화와 달리, 대다수 사용자는 가장 진보된 AI 모델을 클라우드를 통해 사용합니다. ChatGPT, Claude, Gemini와 같은 주요 서비스들이 모두 클라우드 기반인 것이 대표적인 예입니다. 그러나 프라이버시 보호, 연구 목적, 그리고 통제권 확보 등의 이유로 로컬에서 구동되는 AI 모델의 중요성은 여전히 매우 높습니다. 따라서 온보드 GPU 및 NPU를 탑재한 클라이언트 시스템의 AI 성능을 신뢰성 있고 중립적으로 측정할 수 있는 능력이 필수적입니다.
클라이언트 AI 분야는 하드웨어 및 소프트웨어 공급업체들이 로컬 실행에 최적화된 워크로드 유형과 이를 수행할 최고의 컴퓨팅 자원을 정의함에 따라 끊임없이 변화하는 영역입니다. 이러한 급변하는 환경을 파악하는 데 도움을 주기 위해, MLCommons 컨소시엄과 산하 MLPerf Client 워킹 그룹은 주요 하드웨어 및 소프트웨어 공급업체들과 협력하여 클라이언트 벤치마크를 유지 및 관리하고 있습니다.
MLPerf Client 1.0이 이전 버전인 0.6 벤치마크 대비 상당한 개선 사항을 거쳐 막 출시되었습니다. 이 새로운 도구는 더 많은 AI 모델을 포함하고, 더 많은 공급업체의 더 다양한 장치에서 하드웨어 가속을 지원하며, 대규모 언어 모델(LLM)과의 광범위한 사용자 상호작용을 테스트합니다. 또한, 일반 사용자들의 접근성을 높일 수 있는 사용자 친화적인 GUI도 탑재했습니다.
MLPerf Client 1.0을 사용하면 Meta의 Llama 2 7B Chat 및 Llama 3.1 8B Instruct 모델의 성능은 물론, Microsoft의 Phi 3.5 Mini Instruct 모델 성능까지 테스트할 수 있습니다. 나아가, 이 버전은 이전보다 더 많은 매개변수와 향상된 기능을 갖춘 차세대 언어 모델 성능 예시로서, 실험적인 Phi 4 Reasoning 14B 모델에 대한 지원도 제공합니다.
MLPerf Client 1.0은 또한 더 광범위한 프롬프트 유형에 걸쳐 성능을 분석합니다. 개발자들이 최근 흔히 요구하는 코드 분석 성능을 측정할 수 있게 되었으며, 실험적 기능으로 4,000 또는 8,000 토큰의 대용량 컨텍스트 윈도우를 사용한 콘텐츠 요약 성능 측정도 가능합니다.
이러한 폭넓은 모델 및 컨텍스트 크기의 범위는 사용자와 같은 하드웨어 테스터에게 더 많은 장치에 걸쳐 광범위하게 확장 가능한 워크로드 세트를 제공합니다. 예를 들어, 본 릴리스에 포함된 일부 실험적 워크로드는 구동에 16GB VRAM을 요구하기 때문에, 통합 그래픽 및 NPU뿐만 아니라 하이엔드 하드웨어까지 부하 테스트할 수 있습니다.
클라이언트 AI의 하드웨어 및 소프트웨어 스택은 매우 유동적이며, 로컬에서 AI 워크로드를 가속화할 수 있는 방식들은 그야말로 방대합니다. MLPerf Client 1.0은 이전보다 더 많은 하드웨어에 걸쳐 이러한 가속 경로를 포괄하고 있으며, 특히 Qualcomm 및 Apple 장치에 대한 지원이 눈에 띕니다. 지원되는 경로는 다음과 같습니다.
벤치마크 버전 1.0은 다음의 실험적인 하드웨어 실행 경로 또한 지원합니다.
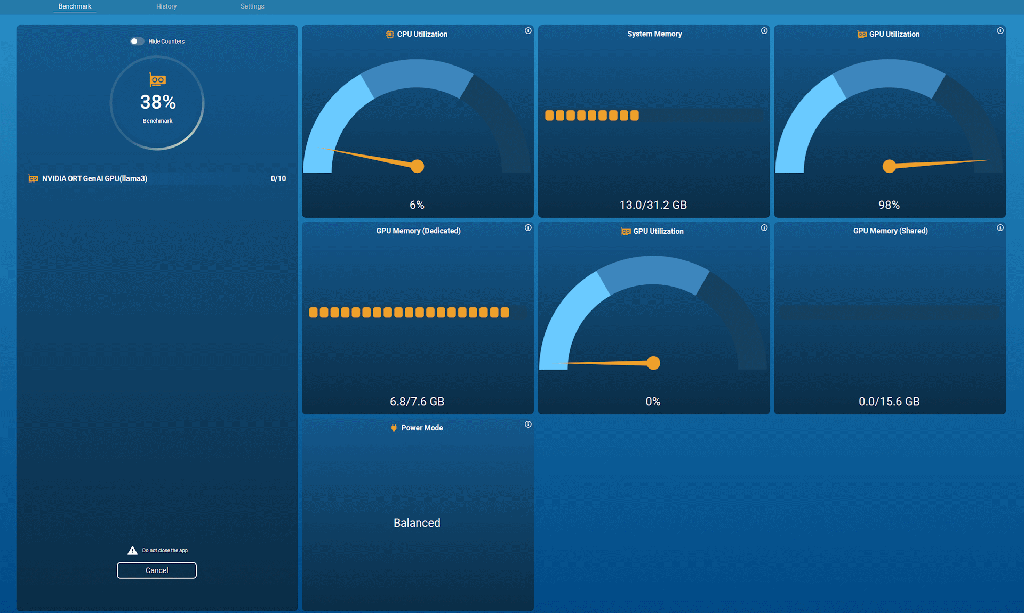
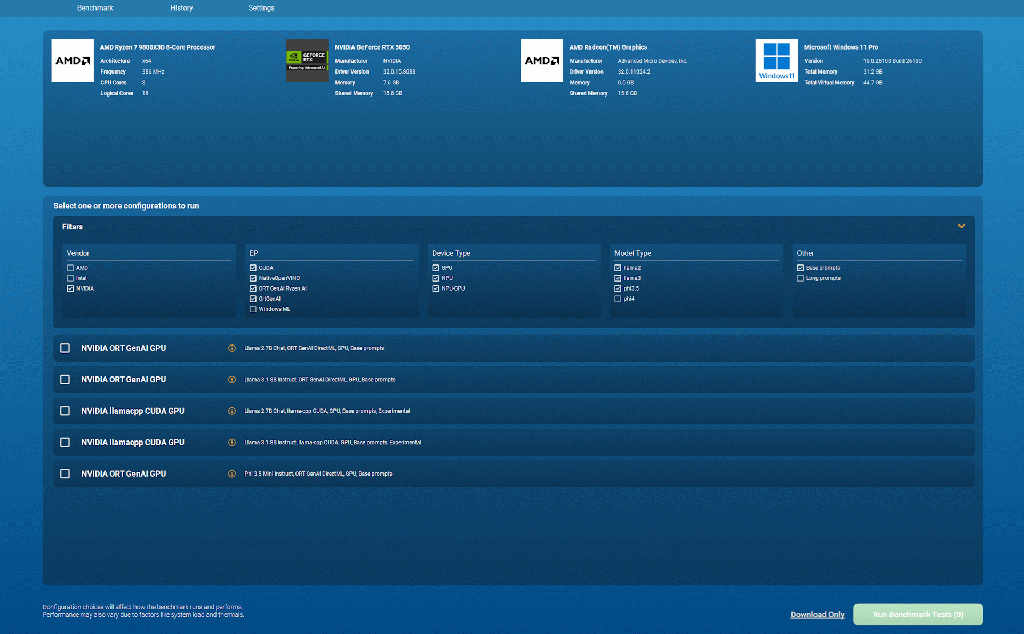
가장 주목할 점은, MLPerf Client 1.0에 그래픽 사용자 인터페이스(GUI)가 제공된다는 것입니다. 사용자는 자신의 하드웨어에서 실행할 수 있는 전체 벤치마크 범위를 쉽게 파악하고 선택할 수 있습니다.
이 GUI 버전은 또한 시스템의 다양한 하드웨어 리소스를 실시간으로 모니터링하여, 선택한 실행 경로가 기대했던 GPU나 NPU를 제대로 사용하고 있는지 한눈에 확인할 수 있게 해줍니다.
이전 버전의 MLPerf Client가 명령줄 전용 도구였던 것에 비하면, 새로운 사용자 인터페이스는 GPU 또는 NPU(혹은 둘 다)의 AI 성능을 가볍게 시험해 보고자 하는 일반 사용자부터, 전문적인 분석이 필요한 사용자까지 폭넓게 만족시킬 수 있습니다.
[추가 내용 없음]