하지만 추론 워크로드에서만.

AI 추론에 사용되는 시스템의 전력 소비 문제에 대한 우려를 해결하기 위해, 하이퍼스케일 클라우드 서비스 제공업체(CSP) 클라우드플레어(Cloudflare)가 AMD나 Nvidia의 AI GPU가 아닌 다양한 AI 가속기를 테스트하고 있다고 월스트리트저널(Wall Street Journal)이 보도했습니다. 최근 클라우드플레어는 Nvidia H200보다 전력 소비는 33% 수준으로 뛰어난 성능을 약속하는 Positron AI의 Atlas 솔루션을 테스트하기 시작했습니다.
Positron은 2023년 설립된 미국 기반 회사로, 추론(inference) 작업에만 전적으로 초점을 맞춘 AI 가속기 개발에 집중하고 있습니다. AI 학습, AI 추론, 기술 컴퓨팅 및 광범위한 다른 워크로드에 맞춰 설계된 범용 GPU와 달리, Positron의 하드웨어는 최소한의 전력 소비로 추론 작업을 효율적으로 수행하도록 처음부터 설계되었습니다. 대규모 트랜스포머 모델을 위한 Positron AI의 1세대 솔루션은 Atlas라고 불립니다. 이 시스템은 8개의 Archer 가속기로 구성되었으며, 전력 효율성을 극대화하면서도 Nvidia의 Hopper 기반 시스템을 능가하도록 설계되었습니다.
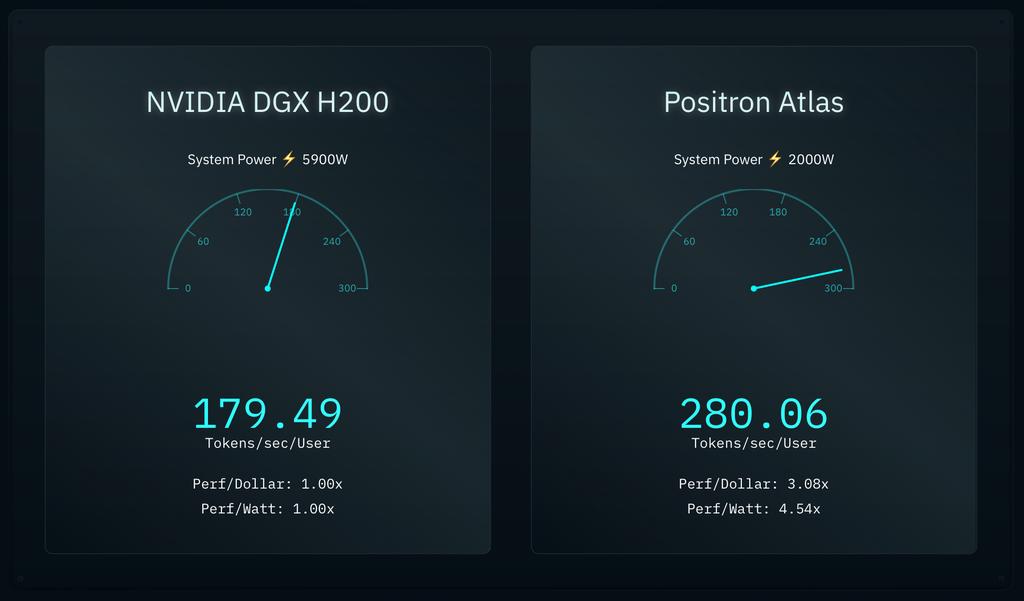
Positron AI에 따르면, Atlas는 BF16 컴퓨팅으로 Llama 3.1 8B 모델을 구동할 때 2000W 전력으로 사용자당 초당 약 280 토큰을 제공할 수 있습니다. 이와 비교하여, 8-웨이 Nvidia DGX H200 서버는 동일한 시나리오에서 5900W라는 막대한 전력을 사용하면서도 사용자당 초당 약 180 토큰만을 달성하는 것으로 자체 비교 분석되었습니다. 이는 Atlas가 성능당 와트(performance-per-watt)와 성능당 달러(performance-per-dollar) 측면 모두에서 Nvidia DGX H200 시스템보다 세 배 더 효율적임을 의미합니다. 물론, 이 주장은 제3자에 의한 검증이 필요합니다.
메타의 새로운 MTIA 라인업, 하이퍼스케일 기업들의 전용 추론 칩 통합 노력에 합류
Positron AI가 ASIC 하드웨어를 애리조나의 TSMC Fab 21에서 제조하며(즉, N4 또는 N5 공정 기술을 사용), 카드 조립까지 미국에서 이루어져 거의 미국산 제품이라는 점은 주목할 만합니다. 그럼에도 불구하고, ASIC이 32GB HBM 메모리와 결합되기 때문에 첨단 패키징 기술이 사용되었을 가능성이 높으며, 따라서 실제 조립은 대만에서 이루어질 수 있습니다.
Positron AI의 Atlas 시스템과 Archer AI 가속기는 Hugging Face 등 널리 사용되는 AI 도구와 호환되며, OpenAI API와 호환되는 엔드포인트를 통해 추론 요청을 처리할 수 있어, 사용자들이 워크플로우에 큰 변화 없이 도입할 수 있습니다.
Positron은 Valor Equity Partners, Atreides Management, DFJ Growth 등 투자자들이 주도한 최근 5,160만 달러 라운드를 포함하여 총 7,500만 달러 이상의 자금을 유치했습니다. 또한 이 회사는 2026년에 Nvidia의 Vera Rubin 플랫폼 기반 추론 시스템과 경쟁할 것으로 예상되는 8-웨이 Titan 머신 형태의 차세대 AI 추론 가속기 Asimov을 개발 중입니다.

Positron AI의 Asimov AI 가속기는 ASIC당 2TB 메모리를 탑재할 예정이며, 회사에서 공개한 이미지에 따르면 HBM 대신 다른 유형의 메모리를 사용할 계획입니다. 이 ASIC은 또한 랙 규모 시스템에서 더 효율적인 작동을 위해 16 Tb/s의 외부 네트워크 대역폭을 갖출 것입니다. 총 16GB 메모리를 갖춘 8개의 Asimov AI 가속기로 구성된 Titan은 단일 머신에서 최대 16조 개 매개변수를 가진 모델을 실행할 수 있을 것으로 예상되어, 대규모 생성형 AI 애플리케이션의 컨텍스트 한계를 크게 확장합니다. Positron AI에 따르면, 이 시스템은 여러 모델의 동시 처리를 가능하게 합니다.
[마무리]
(위 내용은 기술 기사 형식으로 끝맺음 하거나, 별도의 결론 문장을 추가할 수 있습니다.)