AMD의 AI용 소프트웨어 스택은 계속 개선되고 있다.

AMD가 이번 주 가속 컴퓨팅을 위한 오픈 소스 소프트웨어 스택인 ROCm(Radeon open compute)의 7번째 버전을 출시했습니다. 이 버전은 ROCm 6 대비 기존 하드웨어에서의 AI 추론 성능을 대폭 향상시켰을 뿐만 아니라, 분산 워크로드(distributed workloads)를 지원하고 지원 범위를 Windows 및 Radeon GPU로 확장했습니다. 또한, ROCm 7은 최신 Instinct MI350X/MI355X 프로세서에 대한 FP4 및 FP6 저정밀도 포맷 지원을 추가했습니다.
클라이언트 PC를 위한 ROCm 7의 가장 큰 변화는 ROCm이 Windows 및 Radeon GPU까지 확장되어, Ryzen 기반 PC에서 이산형 및 통합형 GPU를 AI 워크로드에 사용할 수 있게 되었다는 점입니다. 2025년 하반기부터 개발자들은 Radeon GPU가 장착된 Ryzen 데스크톱 및 노트북에서 AI 프로그램을 구축하고 실행할 수 있게 되며, 이는 고성능 AI LLM을 로컬 환경에서 구동하고자 하는 사용자들에게 큰 전환점이 될 수 있습니다.

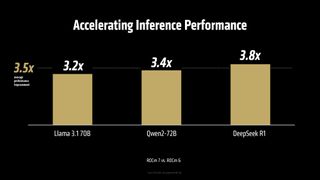
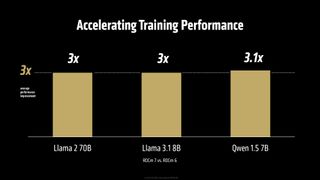
AMD는 AI 하드웨어 시장에서의 소프트웨어 완성도를 중요한 과제로 인식하고 있습니다. 실제로 AMD의 발표에 따르면, ROCm 7을 탑재한 Instinct MI300X는 ROCm 6 대비 3.5배 이상의 추론 성능과 3배의 훈련 처리량(training throughput)을 제공하며 상황이 개선되고 있는 것으로 분석됩니다. AMD는 배치 크기가 1부터 256까지 다양하며 Llama 3.1-70B, Qwen 72B, Deepseek-R1 모델을 구동한 8-way Instinct MI300X 머신 테스트를 진행했으며, 유일한 변수는 ROCm 6 대신 ROCm 7을 사용했다는 점이었습니다. AMD는 이러한 성능 향상이 GPU 활용도 및 데이터 이동성 향상 덕분이라고 설명했지만, 구체적인 내용은 공개하지 않았습니다.
이번 신규 릴리스에서는 vLLM, SGLang, llm-d와 같은 주요 오픈 프레임워크와의 통합을 통해 분산 추론(distributed inference) 기능을 지원합니다. AMD는 이러한 파트너들과 협력하여 공유 컴포넌트와 기본 원시 요소(primitives)를 구축함으로써, 소프트웨어가 여러 GPU에 걸쳐 효율적으로 확장될 수 있도록 했습니다.
더불어, ROCm 7은 FP4 및 FP6과 같은 저정밀도 데이터 타입을 지원합니다. 이는 회사의 최신 CDNA 4 기반 Instinct MI350X/MI355X 프로세서는 물론, 2026년에는 Instinct MI300 시리즈를, 2027년에는 Instinct MI500X 시리즈를 대체할 차세대 CDNA 5 기반 MI400X 및 Instinct MI500X 등 차세대 제품군에 이르기까지 광범위하게 적용될 것으로 기대를 모으고 있습니다.
또한, 개발자들이 활용할 수 있도록 엔드투엔드 솔루션을 제공하는 개발자 키트가 공개되었습니다.
마지막으로, 사용자들이 쉽게 시작할 수 있도록 엔드투엔드 솔루션을 제공하는 개발자 키트를 공개했습니다.

이러한 업데이트는 개발자들이 AI 모델을 로컬 환경에서 쉽게 구동하고 최적화할 수 있도록 돕습니다.