PCIe 추가 카드가 GPU 서버의 메모리 계층 역할을 합니다.

언어 모델의 복잡성과 컨텍스트 윈도우가 확장됨에 따라, GPU에 부착된 고대역폭 메모리(HBM)가 병목 현상을 야기합니다. 이로 인해 시스템은 온보드 HBM에 더 이상 담기지 않는 데이터를 반복적으로 재계산해야 하는 상황에 놓입니다. Blocks와 Files에 따르면, Pliops는 XDP LightningAI 장치와 FusIOnX 소프트웨어를 통해 이러한 문제를 해결했습니다. 이 솔루션은 미리 계산된 컨텍스트를 고속 SSD에 저장해두었다가 필요할 때 즉시 검색합니다. Pliops는 자사 솔루션이 '거의' HBM 수준의 속도를 구현할 수 있으며, 특정 추론 워크플로우를 최대 8배까지 가속할 수 있다고 밝히고 있습니다.
추론(Inference) 과정에서 언어 모델은 컨텍스트를 관리하고 장기 시퀀스 전반의 일관성을 유지하기 위해 키-값(key-value) 데이터를 생성하고 참조합니다. 일반적으로 이 정보는 GPU의 온보드 메모리에 저장되지만, 활성 컨텍스트가 너무 커지면 오래된 항목이 폐기되면서, 해당 데이터가 다시 필요할 경우 시스템이 재계산을 해야 하는 상황이 발생합니다. 이 과정은 지연 시간(latency)과 GPU 부하를 증가시키는 주요 원인이 됩니다. Pliops는 이러한 중복 계산을 제거하기 위해 XDP LightningAI 머신이 구현하는 새로운 메모리 계층을 도입했습니다. 이 PCIe 장치는 키-값 데이터의 이동을 GPU와 수십 개의 고성능 SSD 사이에서 관리합니다.
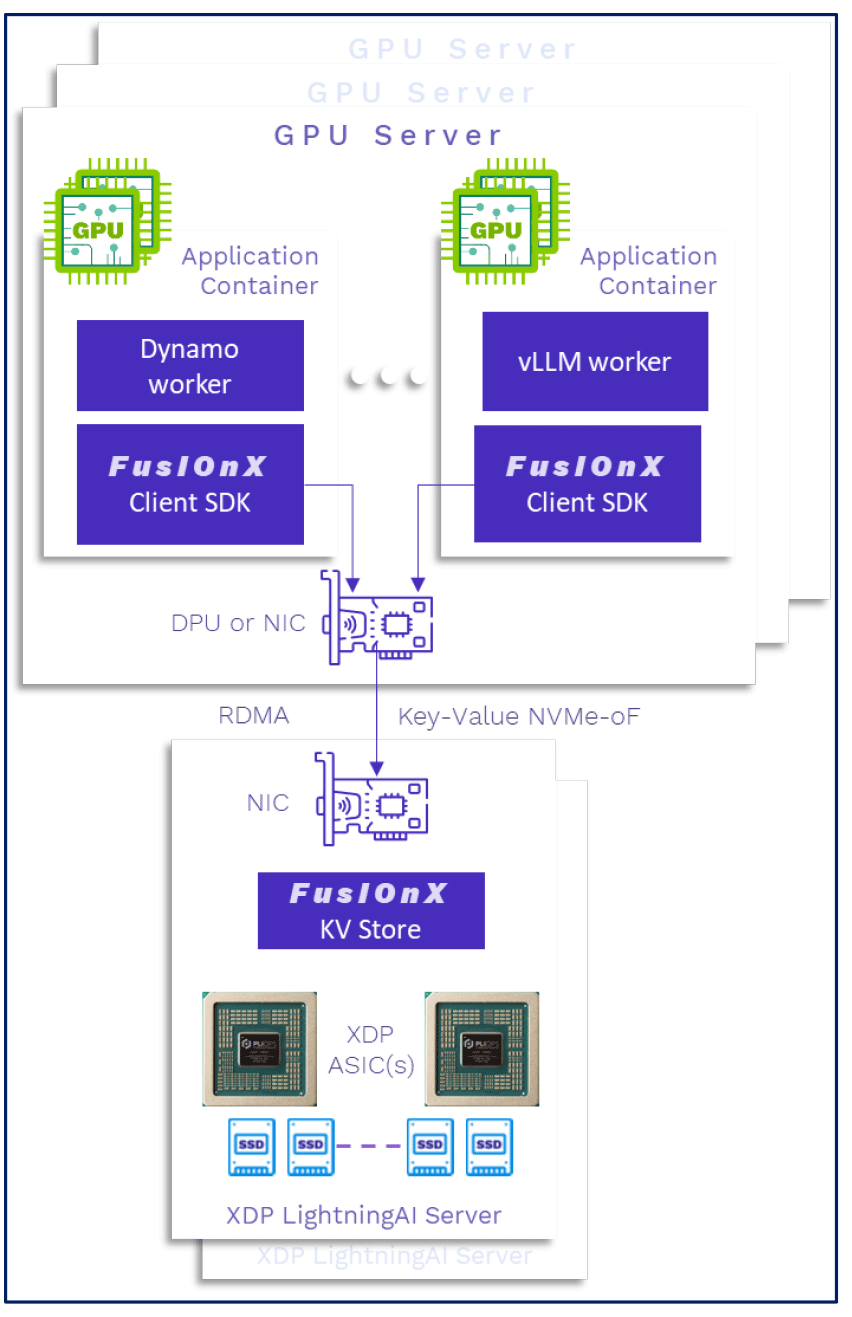
이 장치는 커스텀 설계된 XDP ASIC과 FusIOnX 소프트웨어 스택을 사용하여 읽기/쓰기 작업을 효율적으로 처리하며, vLLM 및 Nvidia Dynamo와 같은 주요 AI 서빙 프레임워크와 통합됩니다. 또한, GPU와 무관하게(GPU agnostic) 독립형 서버 및 멀티-GPU 서버 환경 모두를 지원합니다. 멀티 노드 배포 환경에서는 여러 추론 작업 또는 사용자 간에 캐시된 데이터의 라우팅과 공유까지 처리하여, 대규모 환경에서 지속적인 컨텍스트 재사용을 가능하게 합니다.
이러한 아키텍처를 통해 AI 추론 시스템은 GPU 하드웨어 자체를 확장하지 않고도 더 긴 컨텍스트, 높은 동시성(concurrency), 그리고 더욱 효율적인 리소스 활용을 지원할 수 있습니다. Pliops에 따르면, 추가적인 GPU를 통해 HBM 메모리를 확장하는 것(참고로, 시스템의 최대 확장 가능한 규모, 즉 직접 연결된 GPU 개수는 제한적입니다) 대신, 자사 솔루션은 더 낮은 비용으로 거의 동일한 성능을 유지하며 더 많은 컨텍스트 기록을 보존할 수 있게 합니다. 결과적으로, 이는 까다로운 조건에서도 안정적인 지연 시간으로 대규모 모델을 서비스하는 것이 가능해지며, AI 인프라의 총 소유 비용(TCO)을 절감합니다.
물론, 24개의 고성능 PCIe 5.0 SSD가 336 GB/s의 대역폭을 제공하는 것은 H100의 3.35 TB/s와 비교했을 때 상대적으로 낮은 메모리 대역폭입니다. 하지만 데이터의 반복 재계산 필요성이 제거된다는 점 자체가 XDP LightningAI 장치와 FusIOnX 소프트웨어가 적용되지 않은 기존 시스템 대비 상당한 성능 향상을 제공합니다.

Pliops는 자사 솔루션이 일반적인 vLLM 배포의 처리량(throughput)을 2.5배에서 최대 8배까지 끌어올려, GPU 하드웨어 요구 사항을 늘리지 않고도 시스템이 초당 더 많은 사용자 쿼리를 처리할 수 있도록 지원한다고 밝혔습니다.
최신 뉴스, 분석, 리뷰를 Google News에서 Tom's Hardware를 팔로우하여 받아보세요. 반드시 팔로우 버튼을 클릭해 주십시오.