비디오 디퓨전의 대중화.

GitHub의 Lvmin Zhang이 스탠퍼드 대학교의 Maneesh Agrawala와 협력하여 이번 주에 FramePack을 공개했습니다. FramePack은 고정 길이의 시간적 컨텍스트(temporal context)를 활용하여 비디오 확산(video diffusion) 기술을 실용적으로 구현했습니다. 이를 통해 처리 효율성을 높여 더 길고 고품질의 비디오 생성이 가능해졌습니다. 특히, FramePack 아키텍처로 구축된 130억 개 매개변수 모델은 단 6GB의 비디오 메모리로 60초 분량의 클립을 생성할 수 있습니다.
FramePack은 국소 AI 비디오 생성을 가능하게 하는 다단계 최적화 기법을 활용하는 신경망 아키텍처입니다. 현시점 기준으로, FramePack GUI는 내부적으로 맞춤형 Hunyuan 기반 모델을 구동하는 것으로 알려져 있지만, 관련 연구 논문에서는 기존의 사전 훈련된 모델을 FramePack을 통해 미세 조정(fine-tuning)할 수 있다고 언급하고 있습니다.
일반적인 확산 모델은 이전에 생성된 노이즈가 포함된 프레임 데이터로부터 다음, 노이즈가 약간 덜한 프레임을 예측합니다. 예측 과정에서 고려되는 입력 프레임의 개수를 시간적 컨텍스트 길이(temporal context length)라고 하며, 이는 비디오 크기에 비례하여 증가합니다. 표준 비디오 확산 모델은 대규모 VRAM 풀을 요구하며, 보통 12GB가 일반적인 시작점입니다. 물론 메모리가 부족한 환경에서도 작동할 수는 있지만, 그 대가로 클립 길이 단축, 품질 저하, 긴 처리 시간이 불가피합니다.
다음으로 Nvidia의 DLSS 4.5 Dynamic Multi Frame Generation과 그 5X 및 6X 배율을 다루어 보겠습니다. 이 기능은 생성 프레임 수를 늘려 사용자의 모니터 주사율에 최적화된 프레임을 맞춤 제공합니다.
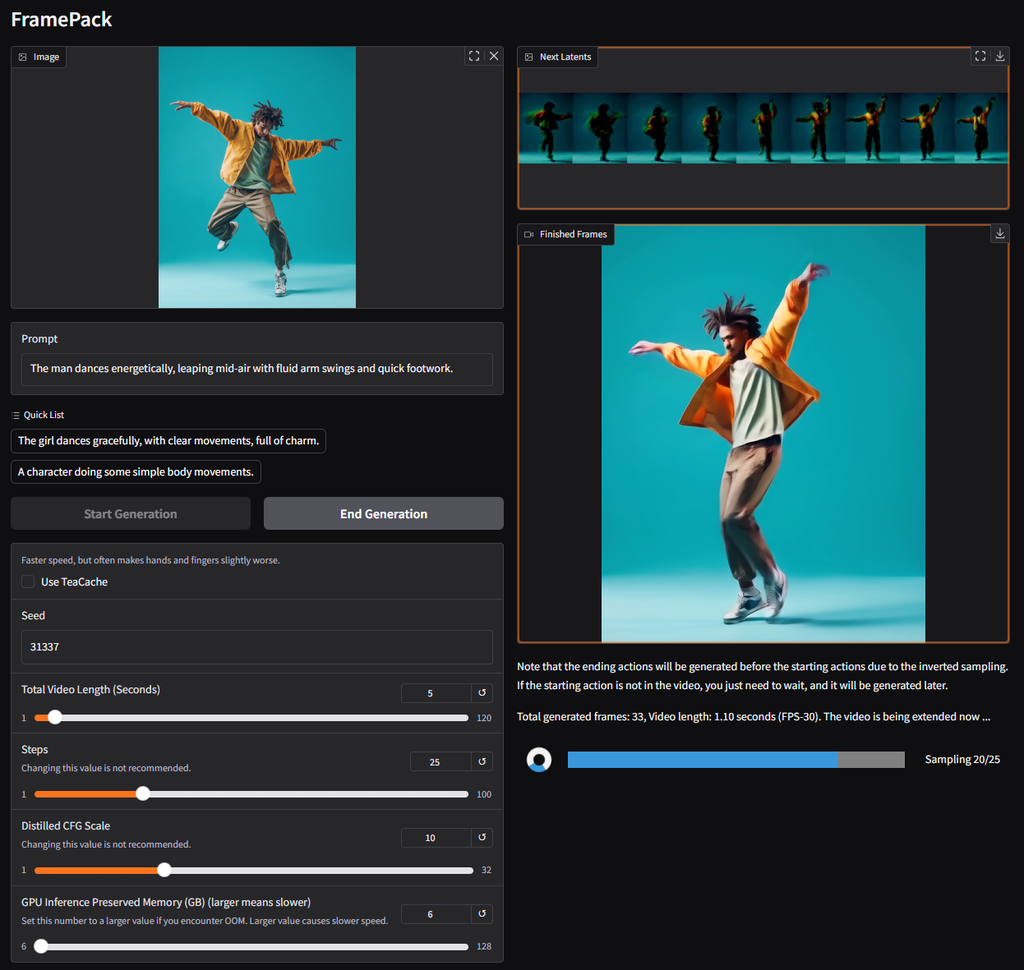
FramePack을 살펴보면, 이 새로운 아키텍처는 입력 프레임을 중요도에 따라 고정된 크기의 컨텍스트 길이로 압축함으로써 GPU 메모리 오버헤드를 획기적으로 줄입니다. 원하는 컨텍스트 길이의 상한선에 수렴하려면 모든 프레임을 반드시 압축해야 합니다. 논문 저자들은 이러한 계산 비용이 이미지 확산에 가하는 비용과 유사하다고 설명합니다.
또한, 비디오 길이가 길어질수록 품질이 저하되는 '드리프팅(drifting)' 현상을 완화하는 기술이 결합되어, FramePack은 화질 손실을 크게 감수하지 않으면서도 더 긴 비디오 생성을 제공합니다. 현재 FramePack은 FP16 및 BF16 데이터 형식을 지원하는 RTX 30/40/50 시리즈 GPU가 필요합니다. Turing 및 이전 아키텍처에 대한 지원 여부는 아직 확인되지 않았으며, AMD/Intel 하드웨어에 대한 언급은 없습니다. 다만 Linux는 지원하는 운영 체제 중 하나입니다.
RTX 3050 4GB를 제외한 대부분의 최신 (RTX) GPU는 6GB 메모리 요구 사항을 충족하거나 초과합니다. 속도 면에서는 RTX 4090이 teacache 최적화를 거쳐 최대 0.6 프레임/초에 달할 수 있으나, 실제 성능은 사용자의 그래픽 카드에 따라 차이가 있을 수 있습니다. 어떤 경우든, 각 프레임은 생성되는 즉시 표시되므로 즉각적인 시각적 피드백을 받을 수 있습니다.
다만, 현재 사용되는 모델은 30 FPS로 제한될 가능성이 높아 많은 사용자에게는 다소 제약적일 수 있습니다. 그럼에도 불구하고 FramePack은 고가의 외부 전문 서비스에 의존하지 않고도 누구나 AI 비디오 생성을 쉽게 할 수 있는 길을 열어주고 있습니다. 콘텐츠 제작자가 아니더라도 재미있게 GIF, 밈 등을 만들어 볼 수 있는 흥미로운 도구입니다. 저 역시 여가 시간에 꼭 사용해 보고 싶습니다.
최신 뉴스, 분석, 리뷰를 받아보시려면 Tom's Hardware를 구글 뉴스에서 팔로우하세요. 팔로우 버튼을 클릭하는 것을 잊지 마십시오.