저렴하고 강력하다.

캘리포니아대학교 버클리(University of California, Berkeley)의 AI 연구팀은 박사과정 학생 지아이 패(Jiayi Pan)가 이끌었으며, DeepSeek R1-Zero의 핵심 기술을 단돈 30달러로 재현하여 고성능 모델을 경제적으로 구현하는 방법을 입증했다고 주장했다. 지아이 패는 Nitter를 통해 자신들의 팀이 '카운트다운(Countdown)' 게임을 통해 DeepSeek R1-Zero를 재현했으며, 이 30억 개 파라미터 규모의 소규모 언어 모델(Small Language Model)이 강화 학습(Reinforcement Learning)을 통해 자체 검증 및 검색 능력을 개발했음을 밝혔다.
패에 따르면, 팀은 기본 언어 모델(base language model), 프롬프트(prompt), 그리고 정답 보상(ground-truth reward)으로부터 실험을 시작했다. 이후 팀은 카운트다운 게임을 기반으로 강화 학습을 진행했다. 이 게임은 같은 이름의 영국 게임 쇼를 원작으로 하며, 게임의 한 세그먼트에서 플레이어들은 기본적인 산술을 이용해 할당된 숫자 그룹에서 임의의 목표 숫자를 찾아내는 임무를 수행한다.
팀은 모델이 처음에는 임의의 출력물로 시작했으나, 점차 정답을 찾기 위한 수정(revision) 및 검색과 같은 전술을 개발했다고 설명했다. 한 예시에서는 모델이 답을 제안하고, 이 답이 올바른지 검증한 후, 올바른 해결책을 찾을 때까지 여러 차례 반복 과정을 거쳐 답을 수정하는 과정을 보여주었다.

Anthropic의 Claude Mythos가 사이버 보안 분야에서 가장 포괄적인 AI 모델일 수 있으나, 연구에 따르면 유사한 결과를 훨씬 저렴한 모델로도 달성할 수 있다고 한다.
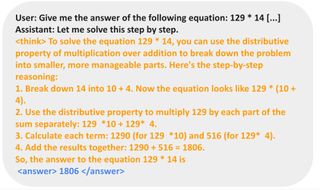
카운트다운 외에도 패는 모델을 사용하여 곱셈 문제도 시도했고, 모델은 다른 기술을 활용해 방정식을 풀었다. 이 모델은 분배 법칙(distributive property)을 이용해 문제를 분해했으며(이는 사람이 큰 숫자를 머릿속으로 계산할 때의 방식과 유사하다), 이후 단계적으로 해결했다.
버클리 팀은 DeepSeek R1-Zero를 기반으로 모델에 다양한 파라미터 크기의 기반 모델을 적용해 실험했다. 처음에는 파라미터가 5억 개에 불과한 모델을 사용했는데, 이 경우 모델은 정답 여부와 관계없이 가능한 해결책을 추측한 후 작동을 멈추는 수준이었다. 그러나 파라미터가 15억 개에 달하는 기반 모델을 사용할 때 모델이 더 높은 점수를 얻기 위해 다양한 기술을 학습시키는 성과를 얻기 시작했다. 파라미터가 30억~70억 개로 늘어날수록 모델은 더욱 적은 단계 만에 정답을 찾아내는 모습을 보였다.
가장 놀라운 점은 버클리 팀이 이를 달성하는 데 약 30달러의 비용만 들었다는 것이다. 현재 OpenAI의 o1 API는 입력 토큰 백만 개당 15달러가 부과되어, DeepSeek-R1의 입력 토큰 백만 개당 0.55달러보다 27배 이상 비싼 가격이다. 패는 이 프로젝트가 특히 낮은 비용을 통해 새롭게 등장하는 강화 학습 확장 연구의 접근성을 높이는 것을 목표로 한다고 강조했다.
한편, 머신러닝 전문가 네이선 램버트(Nathan Lambert)는 DeepSeek의 실제 비용에 의문을 제기하며, 6,710억 개의 LLM 훈련 비용으로 보고된 5백만 달러는 전체 그림을 담지 못한다고 지적했다. 램버트에 따르면 연구 인력, 인프라 등 여러 비용을 고려해야 한다.